

多音色语音合成系统方案
语音合成技术(Text To Speech,TTS)是实现文本到语音转换的关键技术,广泛应用于智能客服、有声阅读、新闻播报等场景,一个高效且高质量的多音色语音合成系统不仅需要支持不同的语言和场景,还需提供多样化的音色选择,并允许自定义诸如音量、语速等参数,以满足更专业或特定场景的需求。
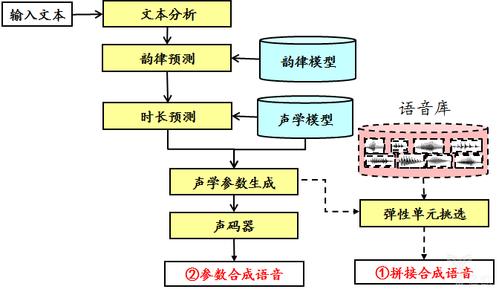
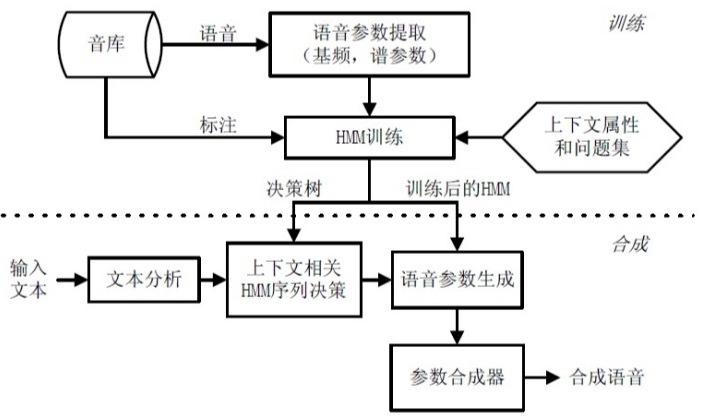
语音合成系统通常由文本预处理、声学模型、语音生成和后期处理四个主要部分组成,文本预处理阶段负责将输入文本分词、进行词性标注和语调预测等,为后续模型提供准确的文本信息,声学模型进一步将处理好的文本转换为声学特征,而语音生成模块则根据这些特征产生对应的语音波形,后期处理模块优化音质,抑制噪声,确保输出语音的清晰度和可懂度。
关键技术与功能实现是评估一个语音合成系统优劣的重要标准,文本预处理的准确性对整个系统的性能至关重要,分词、词性标注、语调预测等处理步骤能够帮助系统更好地理解文本内容及其语境,进而提高语音的自然度和准确性,当前领先的技术如腾讯云语音合成系统,就以其快速的合成速度、自然流畅且高度拟真的语音输出而著称,适用于多种应用场景。
系统设计考虑与实施需关注模型的选择与训练,利用大规模预训练模型,可以大幅提升系统对复杂文本的解析与诠释能力,从而生成更自然的语音,系统的可扩展性和灵活性也非常关键,应能够容易地加入新的音色或调整现有参数,以适应不断变化的市场需求和技术发展。
业务场景适用性是衡量系统实用性的重要方面,一个优秀的多音色语音合成系统不仅能在智能客服中提供稳定服务,还应能在有声阅读、新闻播报等多种场景下表现良好,通过支持SSML标记语言,用户可以更精细地控制语音的表达,如音量、语速等,使发音更符合特定场景的要求。
随着AI技术的不断进步,未来的多音色语音合成系统将更加智能化和个性化,它们将能更好地理解和处理各种语言和口音的文本,同时提供更加自然流畅的语音输出,系统的设计和应用也将更加注重用户体验,使得人机交互更加流畅和自然。
相关问答FAQs:
Q1: 如何选择合适的语音合成系统?
A1: 在选择语音合成系统时,应考虑其技术成熟度、支持的语言和场景、输出语音的质量、系统的可扩展性及客户服务等因素,优质的系统应具备高度自然的语音输出、快速响应时间以及良好的用户定制性。
Q2: 语音合成系统在隐私保护方面有哪些考量?
A2: 高级的语音合成系统在设计时会充分考虑数据安全和隐私保护,这包括使用加密技术保护数据传输和存储的安全,实施严格的数据访问控制,以及遵守相关的法律法规来处理用户数据。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/782290.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复