


倒序索引和MapReduce提取数组


倒序索引概念与作用
倒序索引是一种数据结构,它能够快速地定位一个或多个特定的搜索词,在哪些文档中出现过,这种索引方法与传统的正排索引不同,它不是按照文档来确定内容,而是根据内容来查找文档,这使得倒排索引成为全文搜索领域中的核心数据结构之一。
在信息检索系统中,倒排索引用来储存某个单词或者词组在一组文档中的存储位置映射,这极大地提高了搜索效率,因为系统可以直接通过单词找到含有该单词的所有文档,而无需逐个检查每个文档的内容。
MapReduce编程模型基础
MapReduce是一个编程模型,专用于处理大规模数据集,它将计算任务分为两个阶段:Map阶段和Reduce阶段,在Map阶段,系统将输入数据分割成独立的块,由Map函数处理;而在Reduce阶段,则将所有Map函数的输出整合起来得到最终结果,这种模型非常适合于分布式系统,因为它可以高效地对数据进行并行处理。
在MapReduce框架下实现倒排索引涉及到数据的切分、Map函数生成键值对、可能的Combine优化以及Reduce函数的最终聚合,通过这一流程,可以实现对大规模文本数据的倒排索引构建。
构建倒排索引的步骤

数据处理与Map阶段
在Map阶段,每个Mapper负责处理一部分数据,对于倒排索引的构建,Mapper需要读取文本数据,并解析出其中的单词及其所在的文档标识,它将这些信息转化为键值对的形式输出,其中键是单词,值包含文档标识和出现的位置等信息。
可选的Combine阶段
Combine阶段是一个本地聚合过程,它发生在Map和Reduce之间,Combiner会对同一个Mapper输出的数据进行局部聚合,减少数据在网络中的传输量,对于倒排索引来说,同一个文档中的相同单词可以在这里先被汇总,从而减少后续Reduce阶段的处理压力。
Reduce阶段
在Reduce阶段,Reducer会接收来自不同Mapper(或Combiner)的键值对,并根据键即单词来聚合所有的值,形成完整的索引条目,在这个过程中,所有出现同一单词的文档信息会被整合到一起,形成最终的倒排索引列表。
倒排索引文件的生成与应用
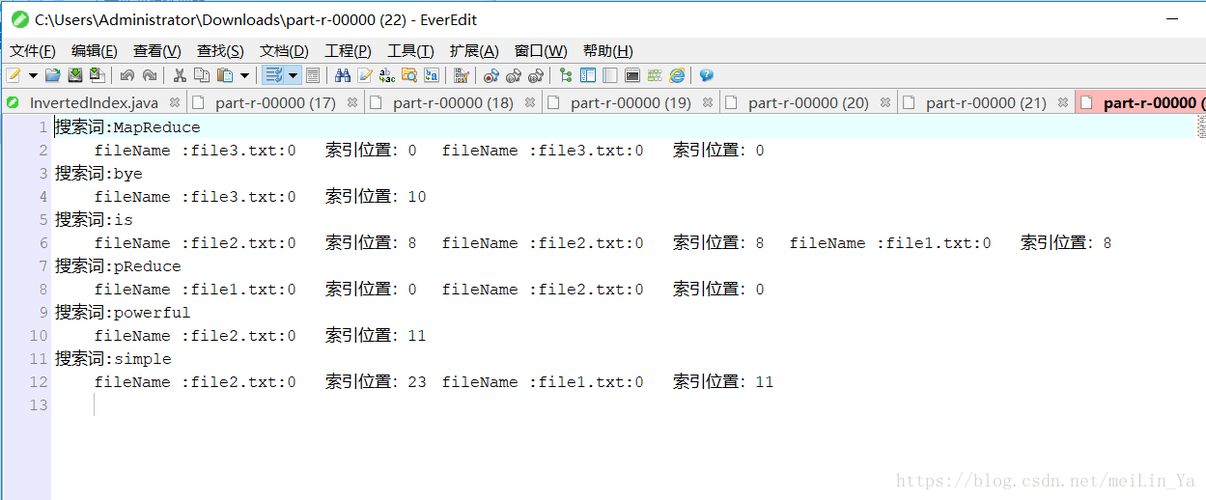
生成的倒排索引文件通常包含了一个单词条以及对应的文档列表,这个文件可以被用来快速查找哪些文档中包含特定的单词,假设有三个源文件file1.txt、file2.txt和file3.txt,通过MapReduce处理后,我们可以得到一个包含这些文件内容的倒排索引文件,从而高效地检索包含“simple”或“powerful”等单词的文档。
相关FAQs
什么是倒排索引中的停用词?
停用词是在信息检索系统中常遇到的一些常见词,如“the”、“is”、“at”等,它们通常对于搜索没有实际的意义,在创建倒排索引时,这些词通常会被过滤掉,以减少索引的大小并提高搜索效率。
MapReduce中的Combiner有何作用?
Combiner是MapReduce中的一个可选环节,它的作用是在数据从Map传递到Reduce之前,先在本地进行一次合并操作,这样可以有效地减少数据在网络上的传输量,同时减轻Reduce阶段的负载,优化性能。
通过上述深入分析,我们可以看到,倒排索引结合MapReduce可以有效地处理和检索大规模的文本数据,这不仅为搜索引擎提供了强大的后盾,也为数据分析开辟了新的可能性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/781836.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复