


bash,cp r /path/to/your/website/directory/* /path/to/your/recycle/bin/,`,,请将/path/to/your/website/directory替换为你的网站目录的实际路径,将/path/to/your/recycle/bin`替换为你的回收站的实际路径。关于如何将Hive中的旧数据拷贝进网站目录并确保其进入回收站的问题,下面将详细解释相关步骤和注意事项。

1、Hive回收站基础
回收站功能开启:在Hive中,如果开启了回收站功能,删除的表会临时存放在回收站里面,这为误删除提供了一定的安全保障。
删除操作与回收站:使用DROP TABLE删除的数据会被放入回收站,而使用TRUNCATE TABLE删除的数据则不会进入回收站,删除的表数据保存在回收站的时间取决于设置的保留时长。
空间占用问题:即使是被删除且放入回收站的数据,也依然占用账号下的空间,如果账号空间有限,仅仅通过DROP TABLE来清除数据表是没有效果的,需要手动清空回收站或在删除时排除放入回收站的选项。
2、查看和管理回收站数据
查看已用空间:通过命令hadoop fs du s h hdfs://beh/user/用户名/数据库名可以查看账号下已使用的空间大小(不包括回收站中的数据大小),回收站的数据虽然不计入此处显示的大小,但实际占用空间。
回收站路径:通常情况下,回收站的路径是/user/用户名/.Trash,如果不清楚具体的用户名,可以通过Hive命令行查询特定表的详情来确定。
管理回收站数据:可以使用hadoop fs rm r命令来删除回收站中的数据或清空整个回收站,删除特定表的数据可以用hadoop fs rm r /user/myuser/.Trash/删除日期(或者Current)/user/myuser/mydb/mytable命令完成。
3、从回收站恢复数据
复制回收站数据到原始目录:可以使用hadoop fs cp命令将回收站的数据复制到原始目录下。hadoop fs cp /user/myuser/.Trash/删除日期(或者Current)/user/myuser/mydb/mytable /user/myuser/mydb/mytable可以将数据从回收站复制回原位置。
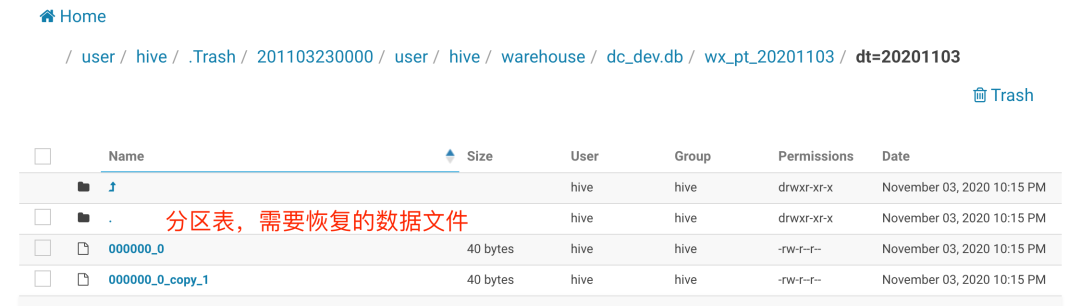
修复分区信息:对于分区表来说,仅复制数据并不足以恢复表中的数据,还需要使用MSCK REPAIR TABLE命令来修复表的元数据信息,执行msck repair table mydb.mytable可以修复分区信息。
4、配置Hive自动移除旧数据至回收站
启用自动移除功能:通过设置hive.overwrite.directory.move.trash参数为true,可以使得执行写目录操作时,旧数据被自动移除至回收站,该配置需要在Hive的配置界面进行设置,并重启Hive实例后生效。
在处理Hive中的数据删除和恢复时,还需考虑以下因素:
版本兼容性:确保所使用的Hive版本支持回收站功能以及相关的数据管理命令。
权限管理:在进行数据删除和恢复操作时,应确保拥有足够的权限,避免因权限不足而导致操作失败。
空间规划:合理规划Hive账号的空间使用,定期检查和清理回收站中的数据,以避免不必要的空间占用。
数据安全:在删除大量数据前,应评估数据的重要性,必要时先进行备份,以防数据丢失。
Hive提供了回收站功能以保护误删除的数据,同时支持通过配置实现旧数据的自动移除,在管理Hive数据时,应充分利用这些特性,结合有效的数据管理策略,确保数据的完整性和安全性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/780913.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复