


DBSCAN(DensityBased Spatial Clustering of Applications with Noise)是一种流行的密度聚类算法,常用于机器学习和数据挖掘中,该算法的核心思想是依据设定的密度阈值将数据点分组成簇,能够有效地发现具有任意形状的簇,并且对噪声数据具有一定的鲁棒性,随着数据量的日益增长,传统的单机DBSCAN算法在处理大规模数据集时面临性能瓶颈,利用MapReduce模型实现并行化处理变得尤为重要,本文将深入探讨基于MapReduce的DBSCAN算法的实现细节及其优势。
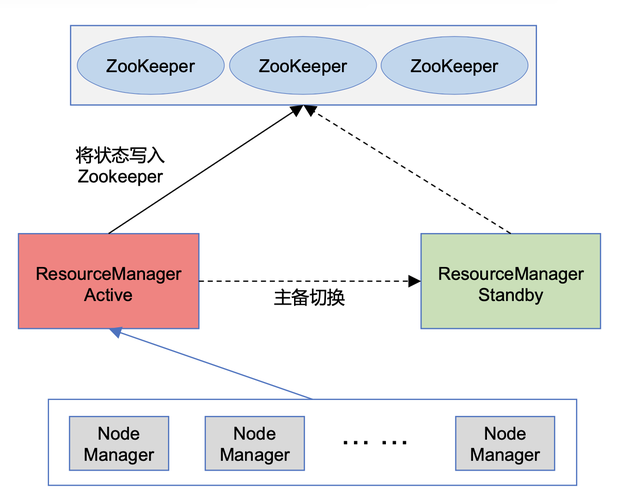

基于MapReduce的DBSCAN算法的具体实现可以分为三个主要步骤:空间划分、邻居点的查找以及聚类结果的形成,在空间划分阶段,通过MapReduce程序将输入的大型数据集划分为多个子空间,这样做的目的是将数据分布到不同的计算节点上,以便于并行处理,每个子空间将被单独处理,从而显著减少了单个节点上的计算负担。
在每个子空间中,使用MapReduce程序找出相邻的点,这一步骤涉及到计算点与点之间的距离,并判断这些距离是否小于或等于用户定义的半径ε,在这个过程中,各个子任务独立执行,极大地提升了算法的处理速度和效率。
通过另一个MapReduce任务将所有子空间中的相邻点连接起来,形成最终的聚类结果,这意味着来自不同子空间但属于同一簇的数据点将被正确地合并,这一步确保了算法的准确性,使得即使数据被分割处理,聚类的结果依然准确无误。
MRDBSCAN算法的一个显著特点是其所有关键子程序都实现了完全并行化,这一点在提升算法性能方面起到了至关重要的作用,由于没有串行处理带来的性能瓶颈,MRDBSCAN可以更高效地处理海量数据。
基于MapReduce的DBSCAN算法不仅解决了传统DBSCAN在处理大规模数据集时的性能问题,还保持了DBSCAN算法原有的优点,如能发现任意形状的簇和对噪声的鲁棒性,通过将数据处理过程并行化,MRDBSCAN显著提高了算法的运行速度和可扩展性,使其成为处理大规模数据集的理想选择。
相关问答FAQs
问: MapReduce如何影响DBSCAN算法的效率?
答: MapReduce模型通过允许DBSCAN算法在多个计算节点上并行处理数据,显著提高了算法的效率,这种并行处理减少了单个节点上的计算负担,加快了数据处理速度,特别是在处理大规模数据集时,能够有效解决传统DBSCAN算法面临的性能瓶颈问题。
问: 使用MRDBSCAN算法处理大规模数据集时需要注意什么?
答: 在使用MRDBSCAN算法处理大规模数据集时,需要注意数据划分的方式可能会影响聚类的质量,因为不恰当的数据划分可能导致边界点的误分类,参数的选择(如半径ε和最小点数MinPts)也非常关键,它们直接影响到聚类的结果和质量,合理选择参数并优化数据划分策略是基于MapReduce的DBSCAN算法成功应用的关键。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/780455.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复