


从Kafka抽取MySQL数据库的实践指南

在当今的数据驱动时代,高效地从分布式消息系统如Kafka中抽取关系型数据库MySQL的数据,已成为许多企业和开发者面临的一个重要技术挑战,本文旨在详细解析这一过程,并提供一个高质量的执行方案。
环境准备与配置
在开始之前,确保开发环境中已经安装并正确配置了Apache Flink, Kafka和MySQL等相关组件,具体步骤如下:
1. 安装Apache Flink
Apache Flink是一个高效的流处理框架,它可以从Kafka接收数据并将其写入MySQL,安装过程中需要添加相关pom依赖,确保包含flinkclients, flinktableapiscalabridge, flinktableplanner等模块。
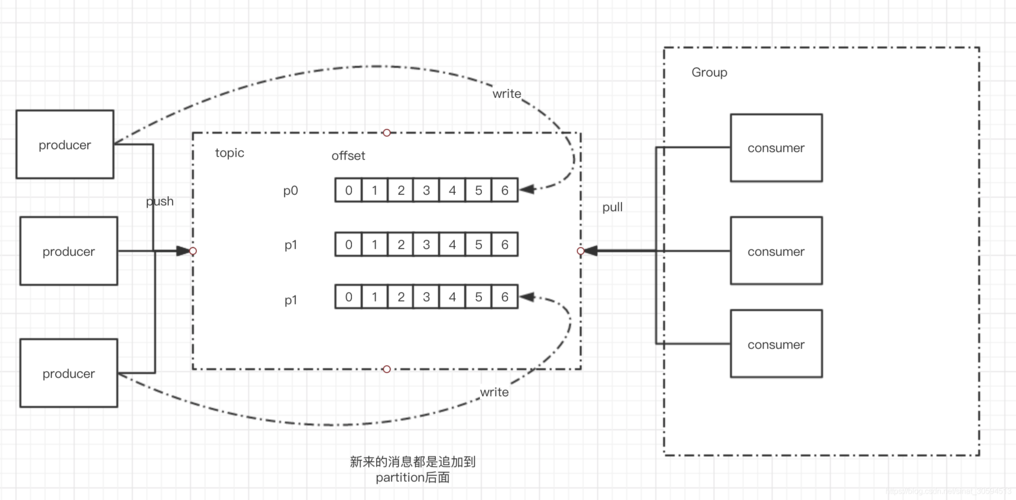
2. 配置Kafka消息队列
启动zookeeper和kafka服务,并创建一个名为east_money的topic,用于数据的传输,使用命令行工具或编写脚本来生产数据,模拟实际的业务数据流。
3. 准备MySQL数据库
初始化mysql表,并确保表结构满足需求,示例中创建了一个名为t_stock_code_price的表,用于存储股票代码及价格信息。
实现数据流转换
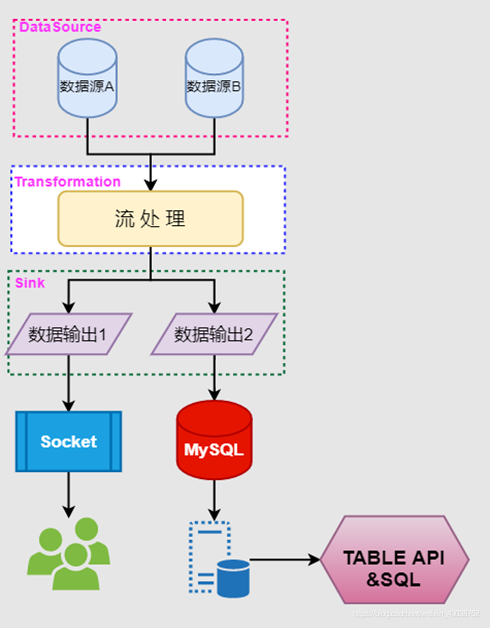
我们将探讨如何实现从Kafka到MySQL的数据流转换。
1. Kafka作为数据源
将Kafka作为数据源,利用Flink的强大能力进行数据处理和转换,通过Flink的Table API和SQL接口,可以方便地实现数据的实时流处理。
示例代码:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new FlinkKafkaConsumer<>("east_money", new SimpleStringSchema(), properties));
DataStream<String> stream = env.fromElements("CREATE TABLE kafka_table (...)");
stream.print(); 2. 数据转换逻辑
根据业务需求,可以在Flink中定义转换逻辑,从JSON格式的消息中提取特定字段,然后进行清洗、格式化。
3. MySQL作为下沉数据库
最终将处理过的数据写入MySQL数据库,使用JDBC连接器来实现这一步骤。
示例代码:
DataStream<StockPrice> stream = ...; // 经过转换后的数据流
stream.addSink(JdbcSink.sink(
"insert into t_stock_code_price values (?, ?)", // 插入语句
new PreparedStatementSetter<StockPrice>() {
@Override
public void setValues(PreparedStatement ps, StockPrice value) throws SQLException {
ps.setString(1, value.getCode());
ps.setDouble(2, value.getPrice());
}
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/mydatabase")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("123456")
.build())); 作业分片维度的参考
在进行大规模数据处理时,合理的作业分片是提高性能的关键,不同的数据源对分片的支持程度不同,以下是常见数据源的分片维度参考:
Hadoop系统中的分片策略
HDFS:支持按文件分片。
HBase:支持按Region分片。
Hive:按Hive文件分片(HDFS读取方式时)。
关系型数据库的分片策略
云数据库MySQL:支持按表字段分片,配置“按表分区抽取”时可按表分区分片。
PostgreSQL:支持按表字段分片,同样可在配置时按表分区进行抽取。
NoSQL数据库的分片策略
MongoDB:不支持分片。
Cassandra:支持按token range分片。
消息系统的分片策略
Kafka:支持按topic分片。
最佳实践与归纳
以下是一些从实际操作中归纳的最佳实践:
资源规划:预先评估所需的计算和存储资源,避免因资源不足影响数据处理效率。
数据一致性:在同步任务执行期间,尽可能避免在源数据库上执行DDL操作,以防数据不一致。
监控与调优:实施细致的性能监控,并根据监控结果调整系统配置以优化性能。
结合上述技术和策略,可以有效地实现从Kafka到MySQL的数据流转换,不仅保证数据的完整性和准确性,还可以提高处理效率,支持实时数据分析和决策。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/778503.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复