


针对运行爬虫所需的服务器配置和配置网站反爬虫防护规则以防御爬虫攻击,本文将提供一个全面的指南,在选择合适的服务器配置时,考虑因素包括CPU、内存、存储和网络带宽等。


服务器配置要求:
1、计算资源:
CPU:多核CPU可以显著提高爬虫程序处理的速度,根据需要爬取的数据量和任务的复杂性,选择合适核心数量的CPU,对于大规模数据爬取,推荐使用8核以上的处理器。
内存:内存资源对存储临时数据及运行时缓存至关重要,较大的内存容量可以提升数据处理速度,减少I/O操作频率,针对大规模爬虫任务,建议至少配置16GB以上的RAM。
2、存储空间:
硬盘:选择足够的硬盘空间以存储爬取的数据,使用SSD而非HDD可以提升数据读写速度,从而加快爬虫的整体运行效率。
3、网络带宽:
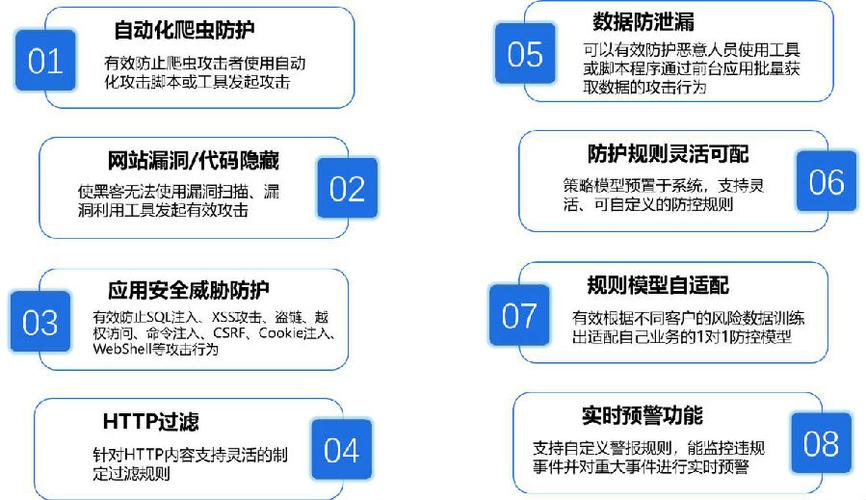
网络:考虑网络带宽的重要性,特别是当爬虫需要高频访问互联网时,高带宽可以保证爬虫在单位时间内访问更多网页,增加爬取效率。
4、操作系统与软件:
系统:Linux系统因其稳定性和高效性成为运行爬虫的首选操作系统,Python是进行爬虫编程的主要语言,其相关库如requests和BeautifulSoup等对爬虫开发极为便利。
反爬虫防护规则配置:
1、Web应用防火墙(WAF):
利用WAF设置具体的防护规则,例如识别特定模式的请求或来自相同IP的频繁请求,并对其进行限制或阻断。
2、场景化配置:
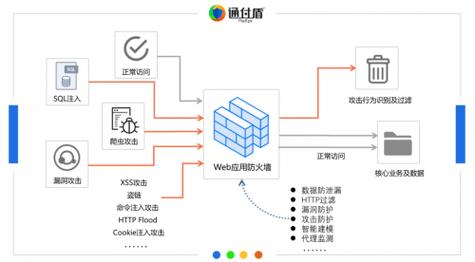
根据不同业务场景定制防爬规则,对于登录页、搜索页的爬虫行为可采取更为严格的限制措施。
3、拦截与记录策略:
设定明确的拦截与记录机制,如发现攻击行为后立即阻断并记录,或是仅记录用于分析但不立即阻断。
4、协同CDN服务:
注意配置与CDN服务的兼容性,确保开启反爬虫防护不会影响到正常的CDN加速服务操作。
在了解了上述关于爬虫服务器的配置和反爬虫防护措施之后,接下来探讨一些实际应用中的常见问题及其应对策略。
FAQs:
1. 如何平衡服务器成本与爬虫效率?
平衡成本与效率主要取决于爬虫的规模和需求,可以考虑租用云服务器,并依据需求调整配置,利用云服务的弹性伸缩功能,在非高峰时段适当降低配置以节省成本。
2. 如何避免误封正常用户为爬虫?
通过设置合理的访问频率限制和利用人机识别技术如CAPTCHA可以避免误封正常用户,分析用户行为模式和请求特征,调整反爬规则,确保不影响正常用户体验。
归纳而言,合理配置服务器资源并有效设置反爬虫防护规则是确保爬虫项目成功的关键,通过上述讨论,应能帮助您更好地理解和实施这些配置和规则,确保爬虫项目的顺利进行,同时保护您的网站免受恶意爬虫的攻击。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/776568.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复