


随着互联网数据的快速增长,爬虫技术成为获取信息的重要手段,随之而来的是网站对于自身数据的保护需求日益增强,在当前互联网时代,配置有效的反爬虫防护规则,对抵御恶意爬虫攻击至关重要,本文将详细介绍如何通过设置网站的反爬虫防护规则来防御爬虫攻击,并提供相关操作步骤和注意事项。
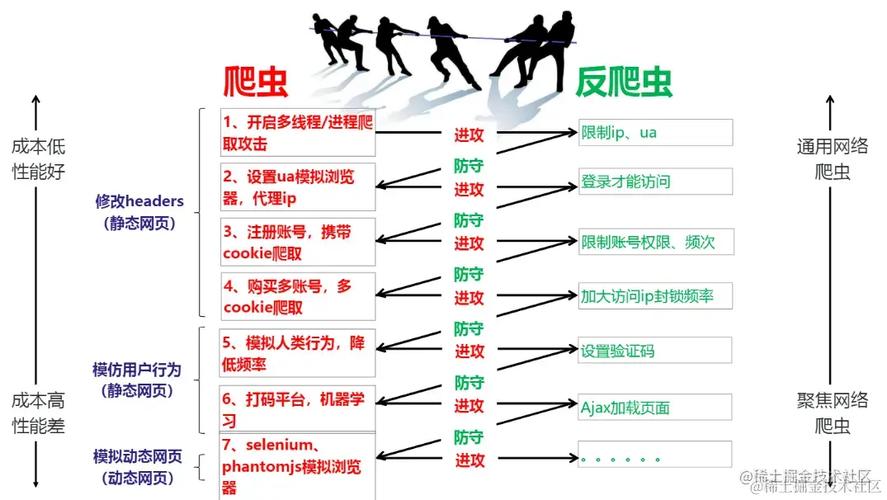

了解反爬虫防护规则的重要性,反爬虫防护规则可以帮助网站防止恶意爬虫的侵袭,保护网站的正常运作和数据安全,这些规则可以针对搜索引擎、扫描器、脚本工具等各类爬虫进行防护,甚至可以通过自定义JS脚本进一步加固防护效果。
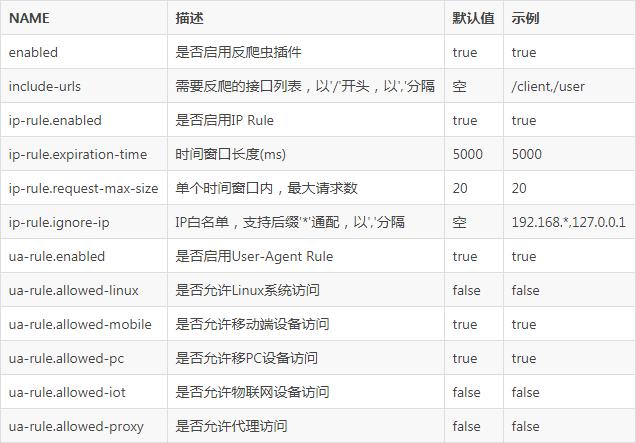
介绍具体的配置步骤,配置反爬虫防护规则首先需要有相应的操作权限,如果您是企业项目的成员,确保您已在“企业项目”下拉列表中选择了正确的项目,并且拥有足够的操作权限,配置过程中,可以根据需求选择拦截或仅记录攻击行为,拦截模式会在发现攻击行为后立即阻断并记录,而仅记录模式则是默认的防护动作,即发现攻击行为后只记录不阻断攻击。
配置反爬虫防护规则时需注意与CDN等服务的兼容性问题,如果当前业务接入了CDN等类型的服务,并同时开启了“网站反爬虫”防护功能,可能会因CDN等服务的加速配置不同而造成访问异常,这要求在配置规则时要充分考虑到现有服务的架构和配置,以避免不必要的服务中断。
为了更深入理解,下面列出了一些具体的配置措施和应用场景:
1、用户行为分析:通过分析访问者的行为模式,识别出非人类的访问行为,频繁的页面请求、不规则的访问路径等可能表明自动化爬虫的行为。
2、IP地址过滤:识别并限制或拦截来自特定IP地址或IP范围的请求,这通常基于已知的爬虫IP地址或地区。
3、定制JS脚本:通过要求访问者执行特定的JS脚本来证明他们是真实用户而非自动化程序。
4、访问频率限制:对来自同一IP地址的请求频率设定限制,超出限制的请求将被暂时拦截或标记为潜在攻击。
5、Headers检查:验证请求中的HTTP Headers是否包含特定的用户代理或引用网址,合法的浏览器请求通常包含完整的用户代理和引用信息。
在实施上述防护措施时,还需定期监控防护效果并调整规则,以适应不断变化的爬虫技术,保持与最新安全策略的同步,不断更新和优化防护措施,以确保网站数据的安全和稳定运行。
配置网站的反爬虫防护规则是维护网站安全、保护数据不被恶意爬取的有效手段,通过设置合适的防护措施并结合现有的安全策略,可以大大降低恶意爬虫攻击带来的风险。
相关问答FAQs
Q1: 如何测试反爬虫防护规则是否生效?
A1: 可以通过模拟爬虫行为,使用自动化脚本尝试访问网站,查看是否能绕过防护规则或被正确拦截,监控日志文件,检查是否有来自测试脚本的请求被记录或拦截。
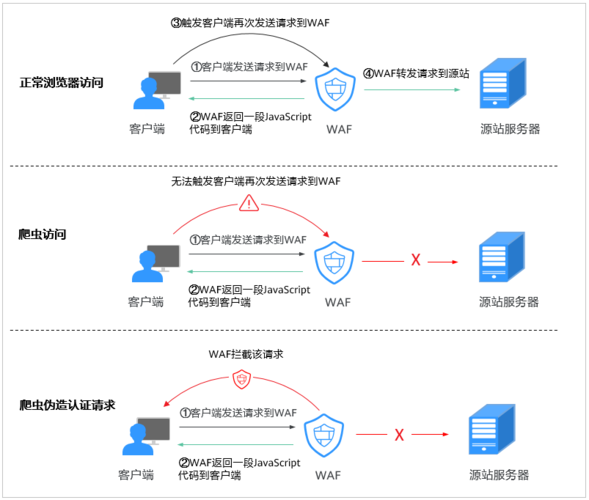
Q2: 反爬虫防护是否会影响搜索引擎的正常索引?
A2: 合理的配置反爬虫防护规则应该不会影响到搜索引擎的正常索引,通过设置特定的规则来识别并允许主流搜索引擎的爬虫(如Googlebot),同时拦截其他未知或明显的恶意爬虫活动。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/776246.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复