


在当今深度学习和机器学习领域,TensorFlow无疑是一个广受欢迎且功能强大的框架,Python 3.6作为该领域的主流编程语言,结合TensorFlow使用,为开发者和研究人员提供了强大的编程能力和灵活性,本文将深入探讨在Python 3.6环境下如何安装和使用TensorFlow,确保读者能够顺利搭建开发环境并运行TensorFlow程序。

一、环境准备与软件安装
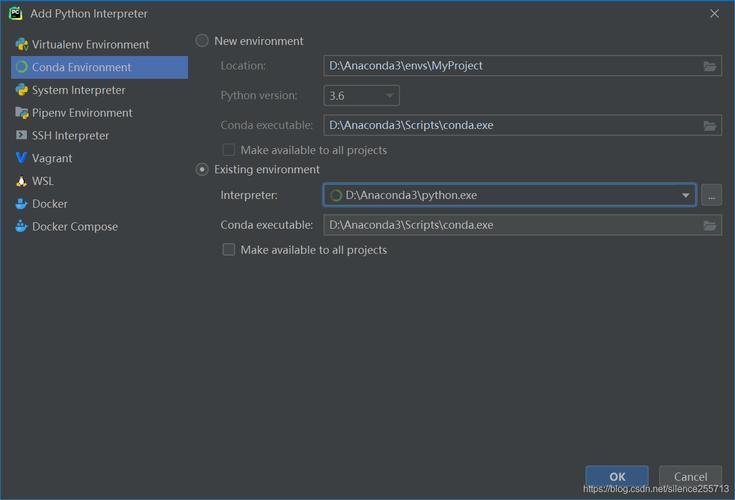
在开始之前,确保系统中已经安装了Python 3.6环境,可以从Python官网下载并安装Python 3.6,安装Anaconda集成环境可以简化后续的库管理过程,通过Anaconda创建一个新的虚拟环境,专门用于安装TensorFlow和其他相关的包,这样可以避免不同项目之间的依赖冲突。
1. 系统和软件要求
操作系统兼容性:TensorFlow支持Windows、Linux和macOS,但某些功能如GPU支持可能取决于特定操作系统的附加组件。
Python版本:TensorFlow建议使用Python 3.6到3.9的版本,确认Python版本可以通过在命令行输入python3 version来完成。
pip版本:确保pip(Python的包管理器)的版本是19.0或更高,使用pip3 version来检查pip的版本。
硬件要求:尤其是使用GPU进行深度学习计算时,需要兼容的NVIDIA CUDA和cuDNN库。
2. 安装TensorFlow
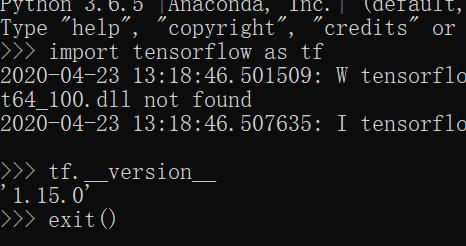
通过pip安装:在命令行界面使用pip install tensorflow命令进行安装,这个命令会自动处理所有依赖关系,并且从PyPI(Python Package Index)下载TensorFlow。
通过Anaconda安装:虽然不常用,但也可通过conda install tensorflow进行安装,不过,conda的包版本更新可能不够及时。
选择CPU或GPU版本:自TensorFlow 2.1起,pip install tensorflow命令默认包含GPU支持,如果只需要CPU支持的版本,可以安装tensorflowcpu包以节省空间和优化性能。
二、TensorFlow基础使用
安装完成后,可以通过编写Python代码来使用TensorFlow,TensorFlow的核心概念是建立计算图,并通过会话执行这些图以获得结果。
1. 创建计算图
定义变量和操作:在TensorFlow中,首先需要定义计算图中的变量和操作,可以定义数学操作、变量赋值等。
数据类型和形状:定义变量时需要指定其数据类型(如float32, int32等)和形状(如一维数组、二维矩阵等)。
自动图编译:TensorFlow有一个自动图编译器,可以将定义的操作转化为优化的计算图。
可视化工具:为了更好的调试和理解,可以使用TensorBoard等工具来可视化计算图。
2. 会话和执行
创建会话:通过tf.Session()创建一个会话对象,这是执行计算图并与TensorFlow运行时交互的桥梁。
运行图:使用session.run()方法来执行计算图中的操作,获取结果。
变量初始化:在执行计算前,必须先初始化所有变量,通常使用tf.global_variables_initializer()。
结果获取:运行结果可以从session.run()返回值中获得,这些结果可以存储在Python原生的数据结构中。
在深入了解了TensorFlow的基本使用之后,接下来将介绍一些实用的技巧和常见问题解决,帮助用户更高效地利用这一强大的工具。
三、实用技巧与问题解决
TensorFlow平台不仅功能强大,还提供了诸多便利的工具和方法,使得模型的开发、调试和部署更加高效。
1. 模型保存和恢复
保存模型:训练好的模型可以使用saver.save()方法保存,以便未来使用或转移到其他系统。
恢复模型:使用tf.train.import_meta_graph加载之前保存的模型和其图结构,再通过saver.restore()恢复变量值。
2. 数据集和预处理
数据集API:TensorFlow提供了tf.dataAPI,可以帮助用户轻松地加载和预处理大量数据。
数据增强:在不增加原始数据的情况下,通过随机变换等方式增加数据的多样性,提高模型的泛化能力。
3. 性能优化
分配足够的内存:确保系统有足够的内存来处理大规模的数据和复杂的模型。
使用GPU加速:TensorFlow可以利用NVIDIA CUDA和cuDNN库来加速计算,显著提升训练速度。
分布式训练:TensorFlow支持在多台机器上分布训练,可以处理超大规模数据集和模型。
四、常见问题解答
随着对TensorFlow的讨论进入尾声,让我们回答一些初学者常问的问题,以便更好地理解和应用这一技术。
Q1:如何在多个GPU上运行TensorFlow?
答案:要在多个GPU上运行TensorFlow,需要将计算图分布到不同的设备上,可以使用tf.distribute.Strategy API,它提供了多种策略如MirroredStrategy或MultiWorkerMirroredStrategy来自动分配变量和操作到不同的GPU上。
Q2:如何优化TensorFlow模型的内存使用?
答案:优化内存使用可以通过几种方法实现:使用tf.function装饰器将函数转换为可即时编译的格式,减少Python堆栈帧的使用;利用@tf.function的autograph功能自动转换Python代码为TensorFlow图;调整批处理大小以控制内存使用。
TensorFlow是一个功能丰富且灵活的机器学习框架,通过合适的配置和优化,可以在Python 3.6环境下发挥出极高的效率,无论是初学者还是经验丰富的开发者,都能从其广泛的社区和丰富的资源中受益,希望本文能帮助您快速入门并有效使用TensorFlow,开启机器学习和深度学习之旅。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/775554.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复