


朴素贝叶斯分类

朴素贝叶斯分类(Naive Bayes Classifier)是一种基于贝叶斯定理的简单概率分类器,它假设特征之间彼此独立,这种算法在文本分类、垃圾邮件检测等领域展示了良好的性能,本文将深入探讨朴素贝叶斯的工作原理、数学基础和实际应用。
基本概念和原理
贝叶斯分类算法基于贝叶斯定理,该定理提供了一种计算条件概率的方法,在贝叶斯分类中,我们关心的是给定某些特征(如单词频率、数值指标等),一个样本属于某个特定类别的概率。
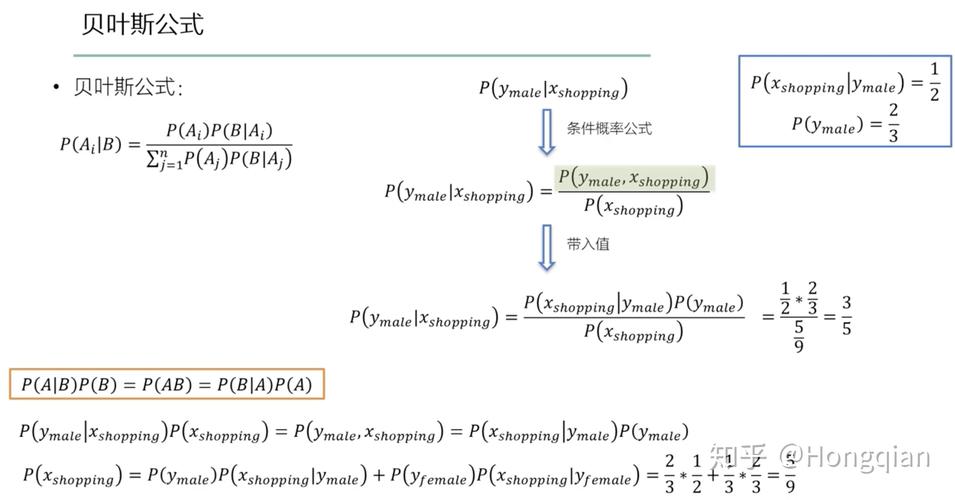
贝叶斯公式
[ P(C mid X) = frac{P(X mid C)P(C)}{P(X)} ]
( C )代表类别,( X )代表特征,( P(C mid X) )是后验概率,( P(X mid C) )是似然性,( P(C) )是类别的先验概率,而( P(X) )是所有类别中特征的边际似然性。
朴素贝叶斯的“朴素”假设
朴素贝叶斯的核心在于其“朴素”(naive)假设,即假设所有特征都是彼此独立的,这意味着,即使实际上特征之间存在某种关联,模型也忽略这些关联。
条件独立性
[ P(X mid C) = P(x_1 mid C) cdot P(x_2 mid C) cdots P(x_n mid C) ]
这一假设简化了计算过程,尽管牺牲了一定的准确率,但在实践中通常能得到不错的结果。
朴素贝叶斯的分类过程
1、数据准备:首先需要准备带有标签的训练数据,每个数据点由一系列特征和一个类别标签组成。
2、先验概率计算:对于每个类别,计算该类别的出现频率作为先验概率( P(C) )。
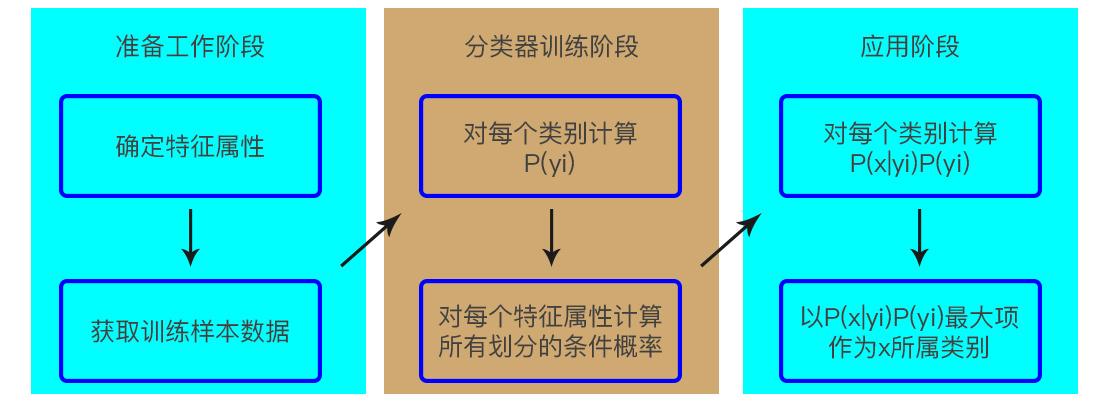
3、似然性计算:对于每个类别,计算每个特征在该类别中的出现频率,然后基于这些频率计算每个特征的条件概率( P(x_i mid C) )。
4、后验概率计算:使用贝叶斯公式计算每个类别的后验概率( P(C mid X) )。
5、分类决策:对于新的数据点,计算其属于每个类别的后验概率,选择概率最高的类别作为该数据点的预测类别。
应用场景分析
朴素贝叶斯在多个领域都有广泛应用,尤其在文本分类中表现突出,可以用于垃圾邮件检测,通过分析邮件中的单词来预测是否为垃圾邮件,它也被用于情感分析,判断文本的情感倾向,以及文档归类,自动将文档分到预定义的类别中。
优缺点讨论
朴素贝叶斯的优点包括:模型结构简单,易于实现和理解;处理高维数据时效率较高;对于大型数据集,尤其是文本数据,表现出奇好的效果。
缺点则主要是其“朴素”假设,忽略了特征之间的依赖关系,这在现实应用中可能不总是成立,尽管对大规模数据集有效,但在数据量较小的情况下,模型的表现可能会受限。
代码实现示例
在Python中,可以使用scikitlearn库轻松实现朴素贝叶斯分类器,使用GaussianNB对鸢尾花数据集进行分类:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
加载数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
创建高斯朴素贝叶斯分类器
gnb = GaussianNB()
训练模型
gnb.fit(X_train, y_train)
预测测试集结果
y_pred = gnb.predict(X_test)
输出模型准确度
print("Accuracy:", metrics.accuracy_score(y_test, y_pred)) 通过这种方式,可以快速评估朴素贝叶斯在不同类型数据集上的表现。
相关问答FAQs
Q1: 朴素贝叶斯分类器如何处理缺失数据?
A1: 朴素贝叶斯能够直接处理含有缺失数据的数据集,当训练集中存在缺失值时,它会根据其他没有缺失的特征来计算概率,大量缺失值可能会影响模型的性能,因此在数据预处理阶段填补或删除缺失值通常是更好的做法。
Q2: 如何优化朴素贝叶斯分类器的性能?
A2: 优化朴素贝叶斯分类器的性能可以从以下几个方面考虑:
数据预处理:确保数据质量,处理缺失值和异常值,进行适当的特征工程。
超参数调整:尽管朴素贝叶斯没有很多可调整的超参数,但仍可以通过交叉验证来优化这些参数。
模型选择:尝试不同的朴素贝叶斯变体(如高斯NB、多项式NB、伯努利NB),看哪种更适合你的数据集。
集成学习:考虑使用集成方法如装袋(Bagging)或提升(Boosting)来提高模型的准确性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/775234.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复