


在数字时代,数据的获取与应用变得尤为重要,Python爬虫和机器学习的结合使用,为数据处理和分析提供了一个高效的解决方案,本文将深入探讨如何通过Python爬虫技术获取数据,并利用机器学习技术进行模型训练和预测,实现从数据采集到智能分析的完整流程。
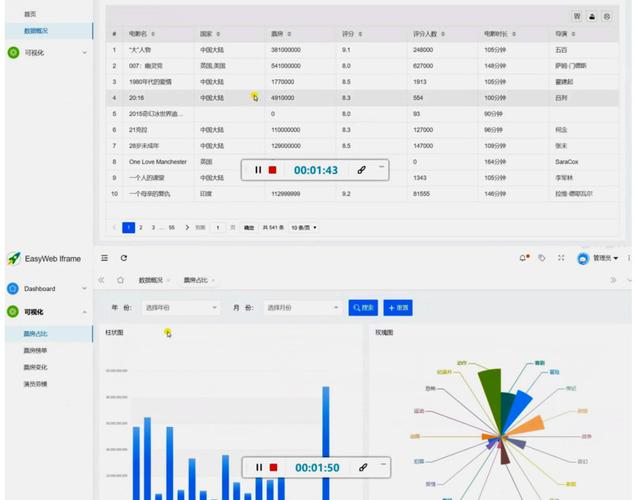

Python爬虫在数据采集中的应用
Python爬虫的基本作用是通过编程方式自动化地从互联网上采集数据,这一过程包括发送HTTP请求、解析网页内容、存储数据等步骤,Python因其简洁的语法和强大的库支持,成为编写网络爬虫的首选语言之一。requests库可以用于发送HTTP请求,而BeautifulSoup和lxml库则能高效地解析HTML文档。
在数据采集过程中,Python爬虫能够定制化地获取所需数据,极大地提高了数据收集的效率和精确度,爬虫技术也被广泛应用于市场调研、竞品分析、舆情监测等多个领域,显示出其广泛的使用背景和强大的实用性。
机器学习端到端学习指南
机器学习项目的实施通常包括几个关键步骤:数据收集、数据预处理、模型选择、训练测试以及模型优化,数据收集是机器学习项目的基础,而Python爬虫则是获取大量网络数据的有效工具,在数据预处理阶段,需要对采集的数据进行清洗和格式化,以适应不同机器学习模型的需求。
选择合适的机器学习模型依赖于具体的应用场景和数据特性,对于分类问题可以选择决策树、随机森林或神经网络模型,模型的训练和测试则是通过已有的数据来训练模型,并通过测试数据来验证模型的准确性和泛化能力,在模型优化阶段,可以通过调整模型参数、特征工程等手段来提升模型性能。
整合Python爬虫与机器学习
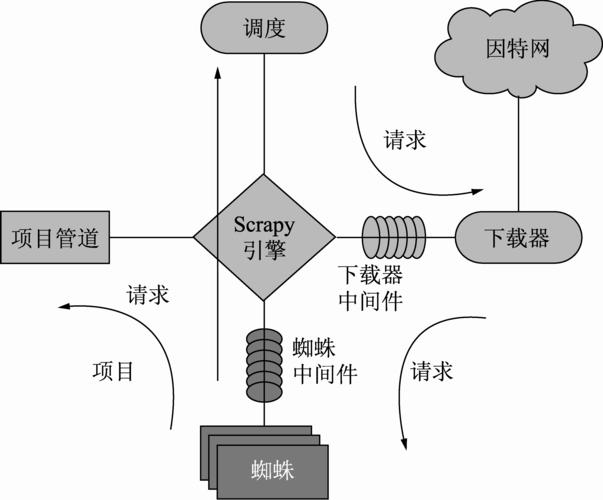
结合Python爬虫与机器学习技术,可以实现从数据采集到智能分析的全链条处理,使用Python爬虫从网络上获取大量的原始数据,这些数据可以是图片、文本或者其他格式,依据具体的应用需求而定,随后,对这些数据进行必要的预处理,包括数据清洗、数据转换等步骤,使其符合机器学习模型的输入要求。
选择合适的机器学习模型进行训练和预测,在这一过程中,可能涉及到参数调优、模型选择等多个环节,以达到最佳的预测效果,这些经过智能分析的数据结果可以用于指导业务决策、趋势预测等,实现数据价值的最大化。
实际应用场景案例分析
假设一家电商公司希望通过分析用户评论来了解某一产品的用户满意度,可以使用Python爬虫技术从电商平台爬取该产品的所有用户评论数据,通过文本分析的机器学习模型,如情感分析模型,来判断每条评论的情感倾向,进而统计出整体的用户满意度,这一过程完全自动化,能快速有效地提供商业洞察。
FAQs
1、Python爬虫会不会侵犯网站版权或个人隐私?
Python爬虫在执行数据采集任务时,确实需要考虑到合法性和伦理性问题,应当遵循robots.txt的规则,避免侵犯版权或个人隐私。
2、机器学习模型如何选择?
机器学习模型的选择应根据具体问题的类型(如分类、回归或聚类等)、数据的特征以及预期的结果精度等因素综合考虑。
归纳而言,Python爬虫与机器学习的结合使用不仅能有效提高数据处理和分析的效率,也能在不同的应用场景中发挥重要作用,如市场分析、用户行为研究等,通过端到端的处理流程,从数据采集到智能分析,这种技术组合为实现数据驱动的决策提供了强有力的支持。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/775037.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复