


1、数据分析
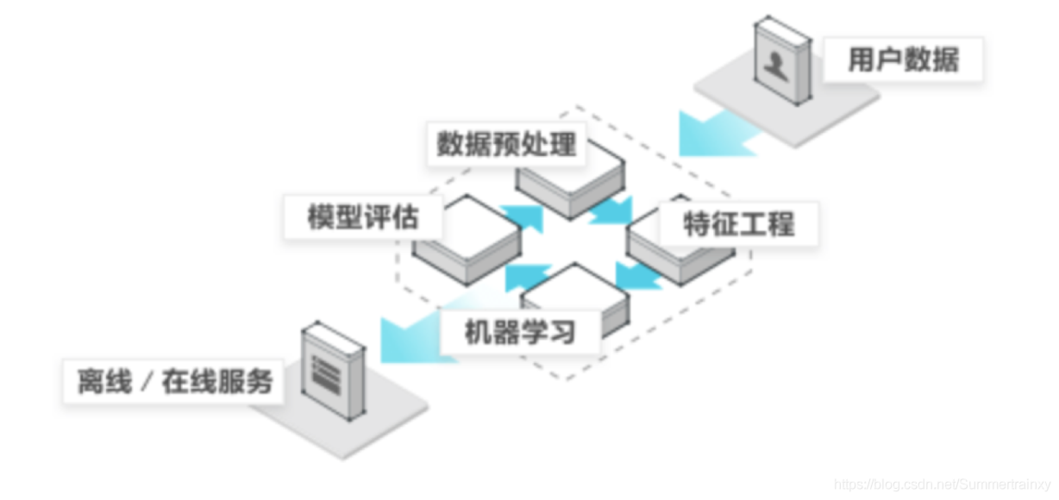

理解数据内容与结构:初步查看数据集中的行列意义、属性类型(数值型或类别型),这有助于了解数据集提供了哪些信息,例如在房价预测中,可能会涉及房屋面积、地理位置等属性。
探索数据关联性:分析属性之间的关联度以及属性与预测目标之间的相关性,这一步非常重要,因为它帮助确定哪些特征可能对模型的预测能力有显著影响。
数据可视化:使用Python的matplot库生成图表,如散点图和直方图,以直观地展示数据分布和属性间的关系,从而更好地理解数据特性。
2、数据清洗
处理缺失值:对数值型数据的缺省值,可以采用均值填充、删除或插值等方法;对类别型数据,可以忽略、填充众数或进行标签编码。
文本数据处理:对于涉及文本的数据,需要进行预处理比如去除停用词、词干提取等,转化为机器学习算法可以处理的格式。
特征缩放:对数据进行标准化或归一化处理,特别在使用基于距离的算法时尤为重要,可以有效地提高模型性能。
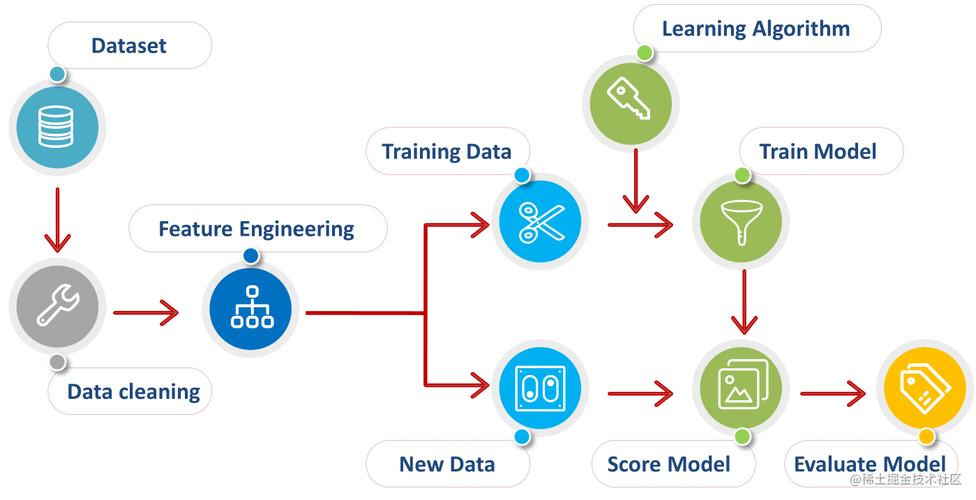
3、特征工程和选择
特征构造:根据现有数据创建新的特征,例如从日期时间数据中提取星期、天的特征。
特征选择:通过统计测试、模型权重或特征重要性排名等方法选择对模型影响较大的特征,这一步骤有助于减少维度灾难的影响,提升模型训练的效率和效果。
4、模型训练与评估
模型选择:试验不同的机器学习模型如决策树、支持向量机等,根据问题的需要选择合适的模型。
超参数调整:通过交叉验证等技术调节模型参数,优化模型性能。
性能评估:使用准确率、召回率、F1分数等指标来评价模型的表现,确保模型达到预定的效果。
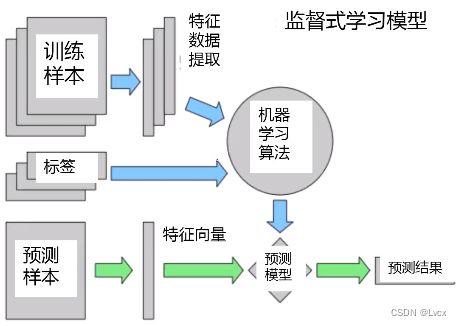
5、模型部署与应用
模型持久化:使用Python的pickle模块或scikitlearn的joblib库保存训练好的模型,以便未来使用。
结果解释与优化:对模型的预测结果进行解释分析,根据反馈继续优化模型。
应用集成:将模型集成到实际的业务或研究场景中,如自动邮件系统、推荐系统等。
相关问答FAQs
Q1: 如何处理机器学习中的过拟合问题?
A1: 可以通过增加数据量、使用正则化技术(如L1、L2正则化)、减少模型复杂度、使用交叉验证等方法来减轻过拟合问题。
Q2: 如何选择合适的机器学习算法?
A2: 根据问题的类型(分类、回归或聚类)、数据的大小、特征的数量和质量以及预期的模型解释性来选择算法,尝试多种算法并比较它们的性能也是常用的做法。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/774901.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复