

在当今数据驱动的时代,时间序列分析成为预测未来趋势和进行决策的关键工具,时间序列数据按时间顺序排列的一系列观测值,如股票价格、气温、销售额等,通过对这些数据的分析可以揭示其内在的发展趋势、周期性变化、季节性波动及随机变异性,本文将深入探讨如何使用Python进行时间序列机器学习的多个方面,从理论基础到实际应用,旨在提供一个全面而准确的时间序列预测指南。
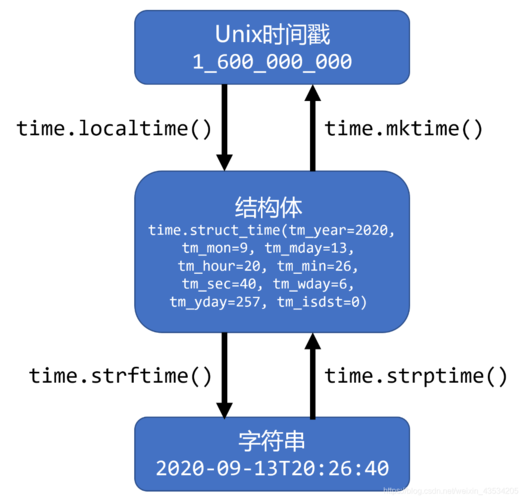

统计建模方法
时间序列预测的一个核心是统计建模方法,包括自回归(AR)、移动平均(MA)、自回归移动平均(ARMA)和自回归综合移动平均(ARIMA)模型,这些方法基于历史数据来预测未来数值,通过分析数据中的自相关性和误差项来实现,ARIMA模型结合了自回归、差分和移动平均三种模型,能有效应对非平稳时间序列数据的预测问题。
机器学习与深度学习技术
随着机器学习和深度学习技术的兴起,传统的时间序列分析方法得到了新的扩展,梯度提升机(GBM)和长短期记忆网络(LSTM)等技术被广泛应用于时间序列数据预测中,GBM通过构建多个决策树来最小化前一个模型的误差,而LSTM则是一种特殊的循环神经网络(RNN),能够学习长期依赖信息,非常适合处理和预测时间序列数据。
核心概念理解
掌握时间序列分析的核心概念对于有效使用Python及其库进行预测至关重要,自协方差、自相关函数等统计量是分析时间序列数据不可或缺的部分,它们帮助研究者识别数据中的潜在模式和结构。
实践案例分析
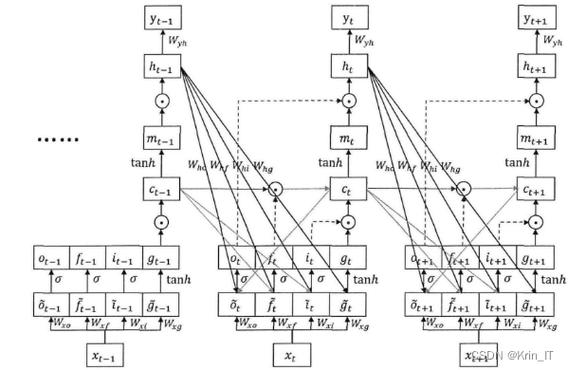
TensorFlow等深度学习框架提供了实现复杂时间序列预测模型的可能,利用CNN和RNN构建的模型能够捕捉时间序列数据中的复杂动态特征,进而提高预测的准确性,通过实际案例的学习,可以更好地理解这些模型如何应用于现实世界的问题,比如能源消耗预测、股市分析等。
时间序列数据处理
在时间序列分析和预测过程中,数据预处理是一个关键步骤,这包括数据清洗、缺失值处理、异常值检测和调整以及数据标准化或归一化,正确处理数据可以显著提高模型的性能和预测的准确性,对数据进行可视化也是一种有效的策略,它可以帮助分析师快速识别数据中的趋势和模式。
评估与优化
选择合适的评估指标对于时间序列预测模型的优化同样重要,常用的评估指标包括均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE),通过交叉验证和超参数调优,可以进一步提高模型的泛化能力和预测精度。
相关问答FAQs
Q1: 如何选择适合的时间序列预测模型?

需要根据数据的特性(如趋势、季节性、周期性)和问题的具体情况来选择模型,对于具有明显趋势和季节性的数据,ARIMA可能是一个好的选择;而对于复杂的非线性模式,可能需要考虑使用基于LSTM的模型,模型的选择还应考虑到预测范围(短期、中期、长期)和可用计算资源。
Q2: 如何处理时间序列数据中的缺失值?
缺失值处理是时间序列数据分析中常见的问题,有多种策略可以应对,如插值法(如线性插值、多项式插值等)、利用相邻数据点的平均值或中位数填充、使用更复杂的模型(如基于时间的随机森林)来估计缺失值,选择哪种方法取决于数据的性质和缺失值的数量。
使用Python进行时间序列机器学习涉及到丰富的理论、方法和工具,从传统的统计建模到现代的深度学习技术,Python的灵活性和强大的库支持使得它成为时间序列分析的首选语言,通过深入理解时间序列数据的特性和相应的模型,结合实际问题的需求,可以有效地预测未来趋势,为决策提供科学依据,不断探索新的方法和技术,解决实际应用中遇到的问题,将进一步推动时间序列分析领域的发展。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/774584.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复