


在当今数据驱动的时代,机器学习作为人工智能的一个重要分支,已经广泛应用于各行各业,Python凭借其强大的库支持和简洁的语法,成为了机器学习领域的首选编程语言,本文旨在通过详细的步骤和实例,指导读者如何使用ScikitLearn构建端到端的机器学习项目,涵盖从基础知识到实践应用的全过程。
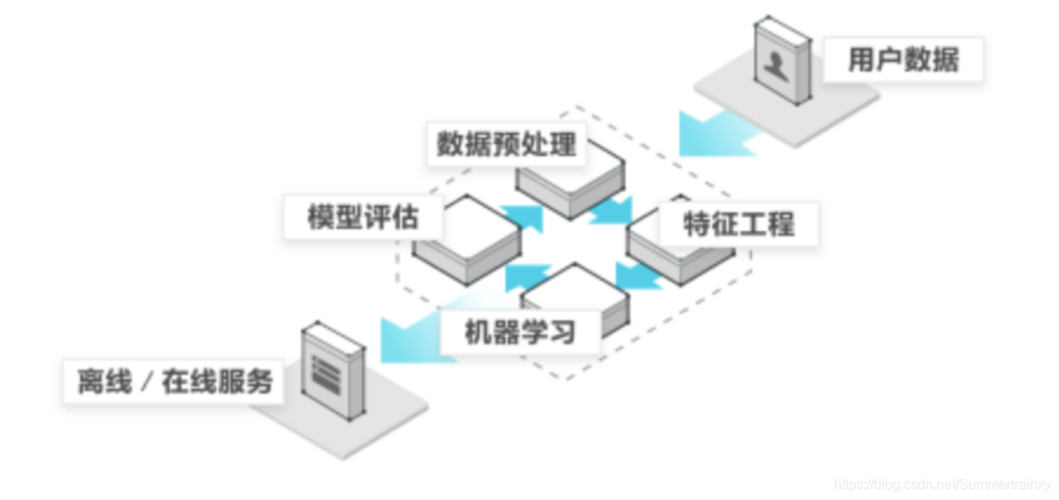

基础知识篇
我们从Python编程的基础知识讲起,涵盖了环境搭建、基础语法,以及机器学习的基础概念和数据预处理技巧,Python机器学习的入门要求对编程语言有一定的了解,包括数据类型、控制结构、函数和类的基本使用,了解机器学习的基本概念,如监督学习、无监督学习、模型评估等,对于后续的学习至关重要。
数据预处理
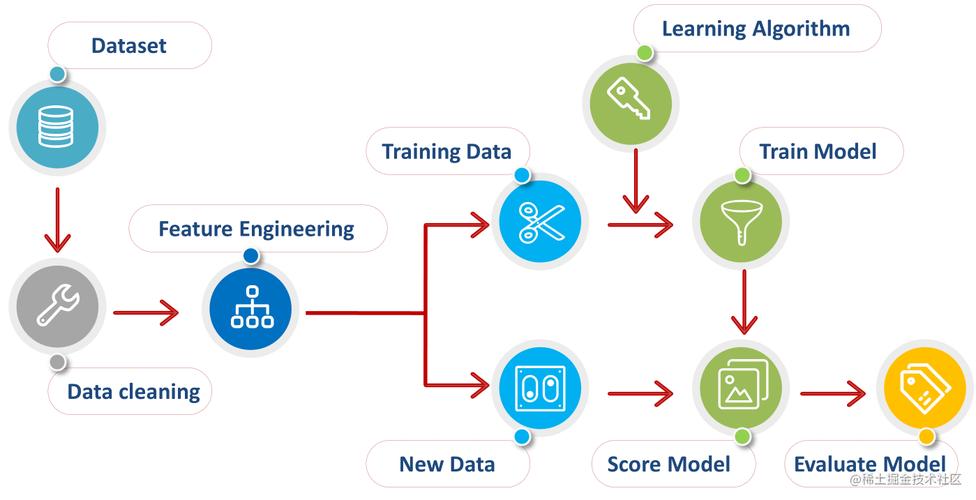
数据预处理是机器学习项目中至关重要的一步,它直接影响到模型的性能,预处理步骤通常包括数据清洗、特征选择、特征工程等,ScikitLearn提供了丰富的数据预处理工具,可以方便地进行数据标准化、归一化、缺失值处理等操作。
算法选择与模型训练
根据问题的类型(分类、回归、聚类等),选择合适的机器学习算法,ScikitLearn提供了广泛的算法选择,包括决策树、随机森林、支持向量机等,模型训练是通过将准备好的数据输入到选择的算法中,让模型学习数据中的模式,这一过程涉及到参数的调整和交叉验证等技术,以达到最佳的模型性能。
模型评估与优化

模型评估是通过一系列指标来衡量模型性能的过程,不同的问题有不同的评估指标,如分类问题的准确率、召回率,回归问题的均方误差等,ScikitLearn提供了模型评估的工具,可以方便地对模型进行评价,模型优化则是根据评估结果对模型进行调整,可能包括参数调优、特征选择优化等,以提升模型的性能。
实践应用
通过具体的实例,如计算机视觉、自然语言处理 (NLP),以及网络、移动、云端和嵌入式运行时的序列建模,可以更好地理解机器学习的应用场景和实现方式,这些实例不仅展示了机器学习技术的实际应用,也提供了丰富的实践机会,帮助读者将理论知识转化为实际操作能力。
相关问答FAQs
Q1: 如何选择合适的机器学习算法?
A1: 选择合适的机器学习算法需要考虑问题的类型(分类、回归或聚类)、数据的特性(特征数量、数据分布)、以及预期的模型性能,实践中,可以通过尝试多种算法并比较它们的性能来选择最合适的算法。
Q2: 如何处理机器学习中的过拟合问题?
A2: 过拟合是指模型在训练数据上表现良好,但在新数据上表现差的现象,处理过拟合的方法包括增加数据量、减少模型复杂度、使用正则化技术以及应用交叉验证等。
归纳而言,Python机器学习从基础到实践是一个系统而复杂的过程,涉及多个环节和知识点,通过上述的步骤和实例,可以帮助读者构建端到端的机器学习项目,掌握Python机器学习的核心技能,随着实践的深入,读者可以不断优化自己的模型,探索更多机器学习的可能性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/774498.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复