


“
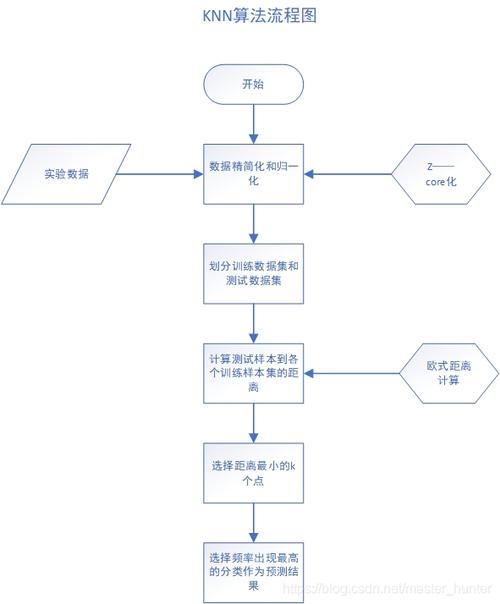
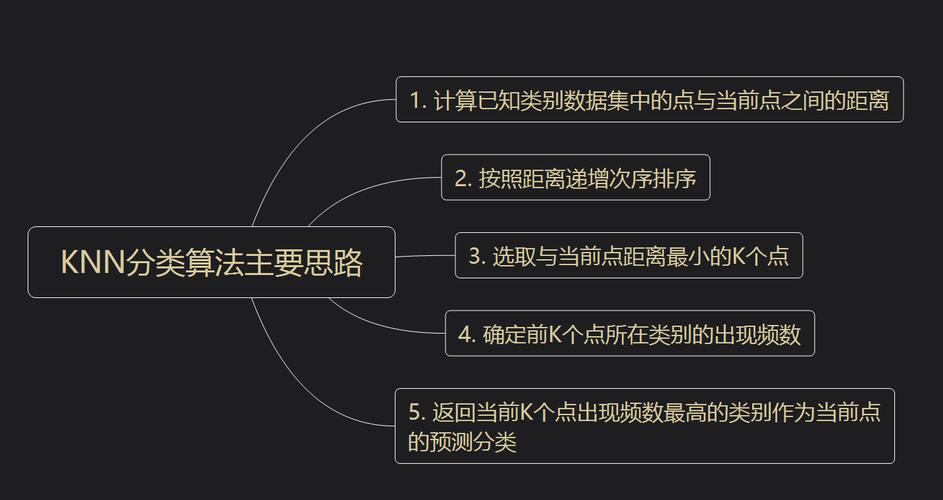
python,from sklearn.neighbors import KNeighborsClassifier,knn = KNeighborsClassifier(n_neighbors=3),knn.fit(X_train, y_train),y_pred = knn.predict(X_test),“kNN(kNearest Neighbors)算法是一种基于实例的分类算法,它的工作原理是:给定一个训练数据集,对于新的输入实例,在训练数据集中找到与该实例最接近的k个实例,这k个实例的多数属于某个类别,则该输入实例也属于这个类别。

(图片来源网络,侵删)
下面是一个简单的Python实现kNN算法的例子:
import numpy as np
from collections import Counter
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 x2) ** 2))
class KNN:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
y_pred = [self._predict(x) for x in X]
return np.array(y_pred)
def _predict(self, x):
distances = [euclidean_distance(x, x_train) for x_train in self.X_train]
k_indices = np.argsort(distances)[:self.k]
k_nearest_labels = [self.y_train[i] for i in k_indices]
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
示例用法
if __name__ == "__main__":
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
knn = KNN(k=3)
knn.fit(X_train, y_train)
predictions = knn.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy) 在这个例子中,我们首先定义了一个计算欧氏距离的函数euclidean_distance,然后创建了一个KNN类,其中包含了fit和predict方法。fit方法用于存储训练数据,predict方法用于对新的输入数据进行预测,我们还定义了一个辅助方法_predict,它负责计算输入实例与训练数据集中所有实例的距离,找到最近的k个邻居,并返回这些邻居中最常见的类别标签。
我们使用鸢尾花数据集(Iris dataset)来测试我们的kNN实现,并将预测结果与实际标签进行比较以计算准确率。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/774173.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复