

开源云存储架构和存储引擎体系架构是现代数据存储技术的关键组成部分,它们对于处理大规模数据集至关重要,下面将详细探讨开源云存储架构的组件、存储引擎的体系结构以及相关的技术进展。
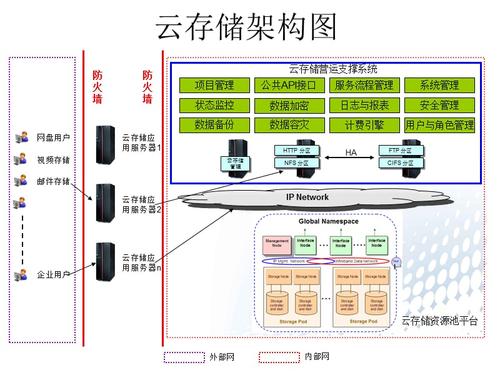
云存储通用框架
云存储系统通常采用层次化的体系结构,其通用框架可分为两大部分:云存储服务和云存储资源池,云存储服务提供了如数据存储、备份、恢复等功能,而云存储资源池则是实现这些服务的基础设施。
云存储服务
云存储服务通过提供接口和工具,使用户能够进行数据的存储和管理,这些服务通常包括:
数据存储:允许用户将数据存储在云端。
备份与恢复:提供数据备份功能,并在需要时恢复数据。
数据迁移:支持数据在不同存储介质之间的迁移。
访问控制:确保只有授权用户可以访问特定的数据。
云存储资源池
云存储资源池是将大量异构存储设备整合成一个统一的资源池,从而实现资源的动态管理和按需分配,这种资源池的设计提高了存储效率并降低了成本,它通常由以下部分组成:
存储节点:负责存放文件的实际存储设备。
控制节点:作为文件索引,监控存储节点间的容量和负载均衡。
内部通信:存储节点与控制节点之间通过至少两片网卡进行通信,一片负责内部节点间的数据迁移和通信,另一片对外提供数据读写服务。
硬件架构
云存储的硬件架构是实现高性能和高可靠性的基础,它主要包括存储节点和控制节点两部分。
存储节点
存储节点负责存放文件,并通过分布式底层存储技术实现数据的冗余备份和容错处理,每个存储节点都具备一定的计算能力,能够处理本地存储的数据,减轻了中心节点的压力。
控制节点
控制节点作为文件索引,负责监控存储节点间的容量及负载均衡,它们通过分布式算法确保数据的一致性和可用性。
分布式底层存储技术
分布式底层存储技术是云存储的核心,它通过将数据分散存储在多个节点上,实现了数据的冗余备份和容错处理,它采用分布式文件系统、分布式缓存等技术,提供高性能的数据读写服务。
关键技术
分布式文件系统:管理跨网络互连的多个计算机上的文件系统。
分布式缓存:提高数据读取速度,减少对底层存储系统的访问。
数据分片与复制:将数据分成多个片段存储在不同的节点上,并进行复制以提高可靠性。
一致性协议:如Raft协议,确保分布式系统中数据的一致性。
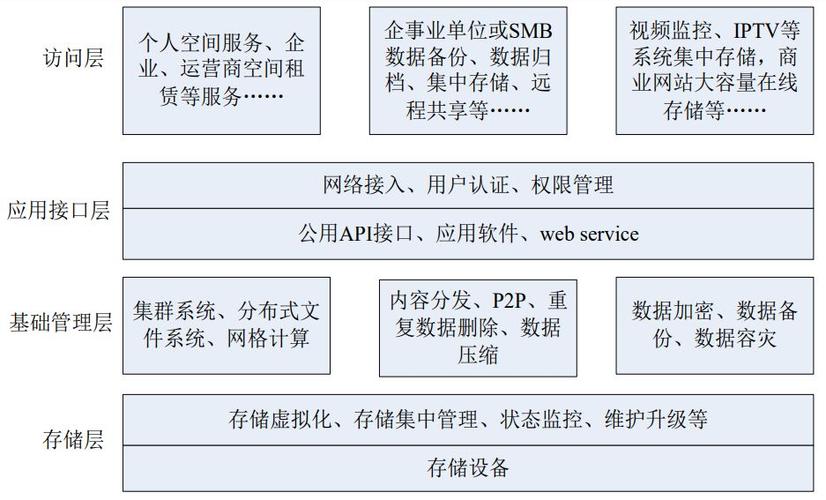
开源存储引擎体系架构
开源存储引擎体系架构通常包括以下几个关键部分:
客户端
客户端是用户与存储系统交互的界面,它提供API和SDK供应用程序使用。
元数据管理
元数据管理负责维护文件系统的结构信息,如文件目录、权限等,它通常由元数据服务器实现,负责处理元数据请求并维护元数据的一致性。
数据管理
数据管理涉及实际数据的存储和访问,它包括:
Chunkserver:负责存储实际数据的服务器。
数据分片:将大文件分割成小块(chunk)分布存储在不同的Chunkserver上。
冗余机制:通过副本或编码技术实现数据冗余,以防数据丢失。
系统监控与管理
系统监控与管理负责监控系统状态、性能指标和维护系统正常运行,这通常包括:
监控系统:实时监控系统的各项指标,如磁盘使用情况、网络流量等。
运维工具:提供系统配置、故障排查和性能优化的工具。
实际应用与案例分析
在实际应用中,云存储架构需要根据具体需求进行规划,对于需要处理大量非结构化数据的场景,可以采用对象存储或块存储等不同类型的云存储服务;对于需要保证数据安全性和隐私性的场景,可以采用加密技术和访问控制等安全措施,以下是一些具体的应用案例:
Curve
Curve是一款高性能、轻量级操作的云原生开源分布式存储系统,它适用于多种场景,如OpenStack和Kubernetes平台,以及云原生数据库的高性能存储,Curve还作为云存储中间件,使用S3兼容对象存储作为数据存储引擎,提供经济高效的共享文件存储。
Curve架构亮点
1、高性能:Curve在随机读写方面表现优于Ceph,并引入了SPDK和RDMA技术提升性能。
2、易运维:采用Raft协议确保高可用性,相对易于理解和运维。
3、云原生:适用于云原生环境,支持PolarDB等云原生数据库。
4、混合存储:利用bcache技术实现混合存储,提升低速磁盘的IO性能。
LakeFS
LakeFS是一种开源数据环境工具,用于管理基于对象存储的数据湖,它将数据存储为具有元数据和唯一标识符的对象,使得数据更易于访问,LakeFS还集成了许多工具并支持Amazon S3和Google Cloud Storage,适用于所有主要数据框架。
LakeFS特性
1、PB级扩展性:可扩展至PB级别数据量。
2、版本控制:通过类似Git的分支和版本控制方法添加数据,易于撤消更改。
3、主流框架支持:适用于Hive、Spark、Presto、AWS Athena等主流框架。
Ceph
Ceph提供对象存储、块存储和文件系统的开源平台,它与Amazon的S3 REST API和OpenStack的API Swift完全兼容,并提供强大的数据访问能力。
Ceph优势
1、多语言绑定:支持Java、C、C++、Python、PHP等多种语言的原生API访问。
2、软件库丰富:拥有强大的软件库支持各种IT基础架构转型。
3、高度兼容性:与S3 REST API和OpenStack API Swift完全兼容。
MinIO
MinIO是一款开源云存储软件,专为大规模数据基础设施设计,它与Amazon S3 API兼容,并且在GitHub上拥有超过26,000颗星。
MinIO特点
1、高性能:适用于大规模非结构化数据存储。
2、开源许可:可在开源Apache V2许可下使用。
3、大数据应用:被许多大数据和机器学习应用程序使用。
OpenIO
OpenIO是一种开源对象存储解决方案,用于管理和保护大量非结构化数据,它允许在任意硬件上部署或云托管,并即时使用额外容量。
OpenIO优点
1、易于管理:提供直观的用户界面简化存储管理员工作。
2、弹性基础架构:可在任意硬件上部署或云托管。
3、大规模设计:专为大规模基础设施和大数据工作负载而设计。
技术比较与选择
在选择开源存储引擎时,应根据项目的具体需求综合考虑以下因素:
1、性能需求:是否需要高性能的随机读写能力?Curve和Ceph在这方面表现优异。
2、易用性和运维:是否需要易于理解和运维的系统?Curve采用Raft协议相对简单。
3、云原生支持:是否需要支持云原生环境和容器编排?Curve和MinIO在这方面有优势。
4、数据安全性:是否需要强大的数据加密和访问控制?考虑选择支持这些功能的引擎。
5、扩展性需求:是否需要支持大规模扩展?LakeFS和Ceph能很好地扩展至PB级别。
6、生态和社区活跃度:选择有活跃社区支持的项目有助于获取更新和技术支持,例如MinIO在GitHub上的星星数量较多。
7、使用成本:考虑总拥有成本,包括初始部署、运维、扩展等方面的费用。
归纳与展望
开源云存储架构和存储引擎体系架构在处理大规模数据方面发挥着重要作用,通过对各个开源存储引擎的分析,可以看到每个引擎都有其独特的优势和适用场景,在选择适合自己需求的存储引擎时,需综合考虑性能、易用性、扩展性和成本等多方面因素,随着技术的不断进步和创新,未来云存储将继续发展和完善,为企业数字化转型提供更加高效、可靠的存储解决方案。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/773258.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复