


${hiveconf:variable}:用于在Hive脚本中引用Hive配置变量。,${env:variable}:用于在Hive脚本中引用操作系统环境变量。,${variable}:用于在Hive脚本中引用Hive脚本内的变量。,,这些宏可以帮助开发者在Hive脚本中动态地引用和操作变量,提高代码的灵活性和可维护性。Hive是一个强大的数据仓库工具,它基于Hadoop平台,提供了类SQL的查询语言HQL(Hive Query Language),使得用户能够以熟悉的方式进行大数据处理,而无需深入了解底层的MapReduce编程,下面将详细介绍Hive应用开发中的常用概念:

1、Hive的基本概念
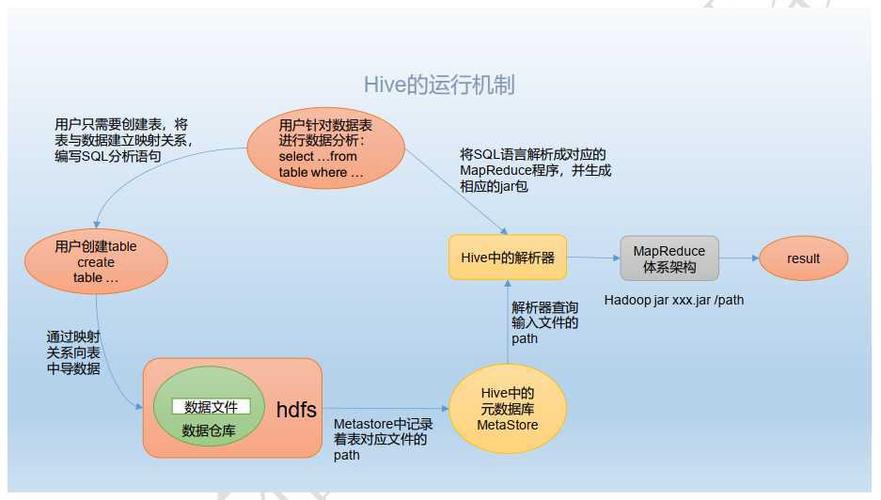
定义:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质:将HQL转化成MapReduce程序,处理的数据存储在HDFS,分析数据的底层实现是MapReduce,执行程序运行在Yarn上。
优缺点:优点是操作接口采用类SQL语法,简单易上手,减少了学习成本;缺点是HQL表达能力有限,效率比较低,调优困难。
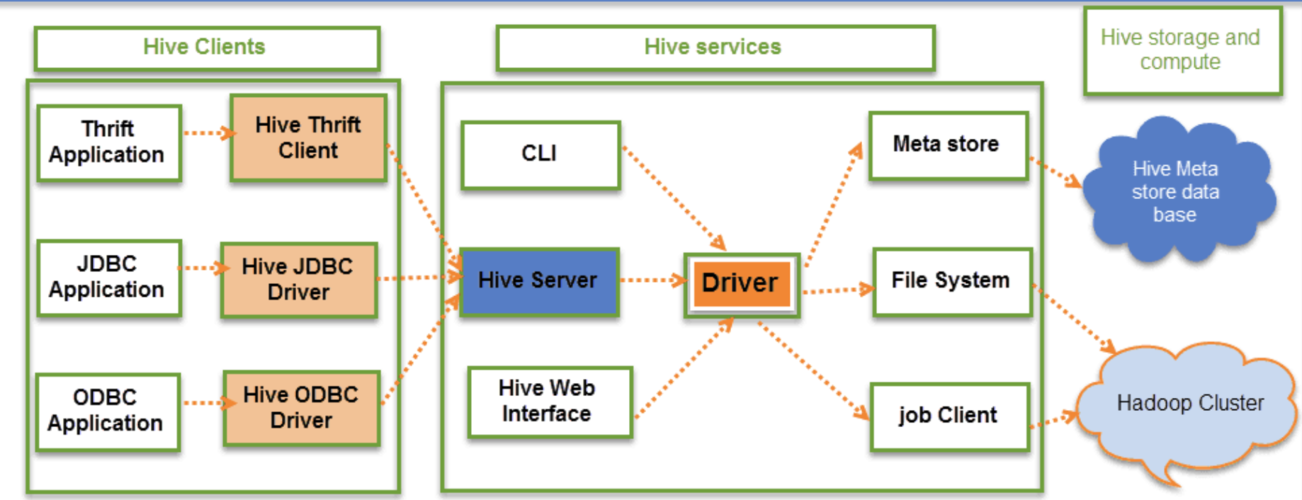
2、Hive架构原理
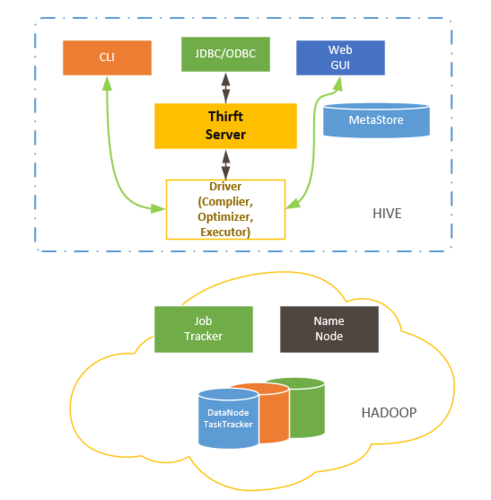
用户接口:包括CLI、JDBC/ODBC、WEBUI等。
元数据:Metastore存储表名、表所属数据库、拥有者、列/分区字段等信息,默认使用Derby数据库,推荐使用MySQL。
驱动器:包括解析器、编译器、优化器和执行器,将用户的HQL指令翻译成MapReduce并提交到Hadoop执行。
3、Hive与数据库的比较
查询语言:Hive使用HQL,类似SQL,便于开发者使用。
数据存储位置:Hive数据存储在HDFS中,而数据库可将数据保存在块设备或本地文件系统。
数据更新:Hive不推荐数据改写,数据在加载时确定;数据库支持频繁数据修改。
执行引擎:Hive查询通过MapReduce实现,数据库有自己的执行引擎。
执行延迟:Hive延迟较高,适合非实时性要求的场景;数据库延迟较低,但受限于数据规模。
4、Hive的数据模型
表:Hive表对应HDFS上的目录,表中的数据文件存储在该目录下。
分区:将表的数据按某些列值划分,提高查询效率。
桶:进一步将分区数据划分成更小单元,优化查询性能。
5、Hive的应用场景
数据仓库:用于存储、管理和查询大规模数据。
数据分析:适用于各种数据分析任务,支持业务决策。
日志处理:广泛应用于日志数据处理,方便查询和分析。
6、Hive常见命令体系
DDL命令:创建、删除数据库和表,创建、删除视图等。
DML命令:插入、更新、删除表中数据。
查询和分析命令:进行数据检索、查询和分析操作。
Hive作为一个数据仓库工具,其在大数据处理方面的强大能力和灵活的类SQL查询语言使其成为企业和开发人员的重要选择,了解和掌握Hive的基本概念、架构原理、数据模型以及常用命令,对于进行高效的Hive应用开发至关重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/773246.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复