



Apache Storm是一种开源的分布式实时大数据处理框架,被称为实时版的Hadoop,随着对实时数据处理的需求日益增加,Storm已经成为流计算技术中的佼佼者和主流,本文将介绍Storm的可伸缩性、主要特性、工作原理以及如何开发Storm应用。
Storm的核心特性与应用场景
1、核心特性
适用场景广泛:Storm可以实时处理消息和更新数据库,支持持续计算和分布式方法调用(DRPC)。
可伸缩性高:通过增加机器和提高任务并行度,Storm可以处理大量消息。
保证无数据丢失:Storm保证每一条消息都会被处理。
异常健壮与容错性好:集群易于管理,节点重启不影响应用。
语言无关性:拓扑和处理组件可以用多种语言定义。
2、应用场景
推荐系统:如实时推荐相关商品。
金融系统:如高频交易和股票分析。
预警系统:如实时安全警报。
网站统计:如实时统计流量和销量。
交通路况实时系统:实时更新交通状况。
Storm的工作原理与架构
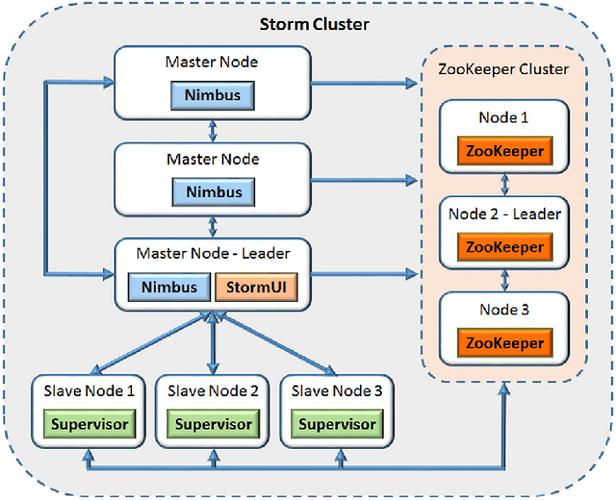
1、Storm集群结构
Nimbus:负责代码分发、任务分配和故障监测。
Supervisor:监听分配给它的节点,启动和关闭工作进程。
ZooKeeper集群:协调Nimbus和Supervisors之间的工作。
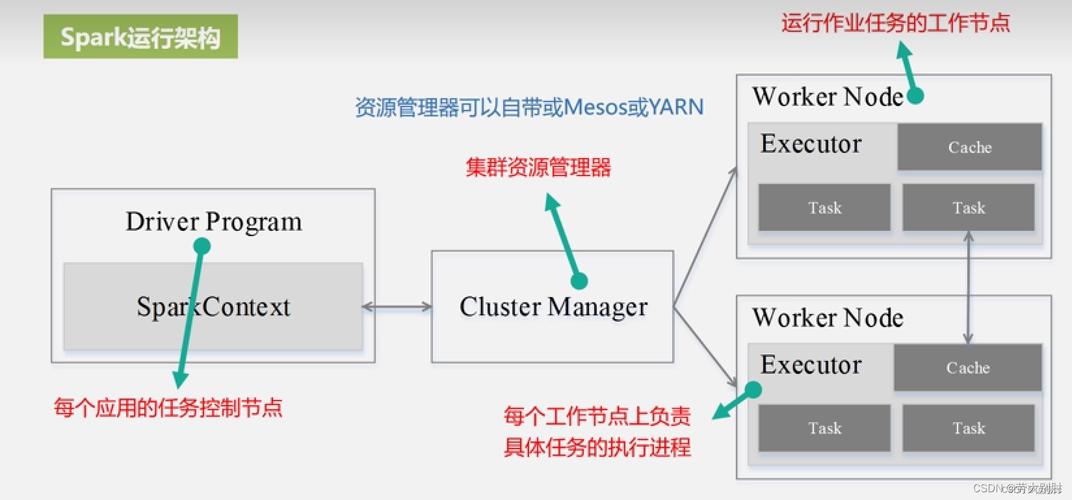
2、Storm工作流程
Spout(管口):数据源,不断发射tuple到topology。
Bolt(处理器):处理输入的tuple,执行过滤、聚合等操作。
Topology(拓扑):逻辑计划,定义Spouts和Bolts的连接。
Storm的可靠性与容错机制
1、元组跟踪与锚定机制
元组跟踪:每个元组被分配唯一ID并跟踪状态。
锚定机制:Bolt可以选择锚定元组,确保失败时重新发送。
2、确认与重试机制
确认(ack)机制:Bolt成功处理元组后发送确认消息。
重试机制:未收到确认的元组会进行重播。
3、事务性Spout
事务性Spout:保证每个批次的数据只被处理一次。
Storm的性能优化与常见问题解决
1、性能优化
拓扑设计:减少shuffle操作和Bolt数量以优化性能。
并行度设置:合理设置Spout和Bolt的并行度以提高速度。
数据序列化:使用高效的序列化框架如Kryo。
2、常见问题解决
数据延迟与倾斜:优化处理逻辑和资源分配,减少计算复杂度。
容错机制理解不足:深入学习Storm的容错机制,正确配置消息确认策略。
示例:简单的单词计数Topology
1、WordCountTopology 示例
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("wordspout", new SentenceSpout(), 1);
builder.setBolt("splitbolt", new SplitSentenceBolt(), 2)
.shuffleGrouping("wordspout");
builder.setBolt("countbolt", new WordCountBolt(), 4)
.fieldsGrouping("splitbolt", new Fields("word"));
Config config = new Config();
config.setDebug(true);
if (args != null && args.length > 0) {
config.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcount", config, builder.createTopology());
}
}
} 这个示例展示了一个简单的单词计数Topology,包括一个Spout用于发送句子,一个Bolt用于分词,另一个Bolt用于计数,通过这些基本组件,可以构建复杂的实时数据处理流程。
Apache Storm因其高可伸缩性、广泛的应用场景和强大的实时处理能力,成为大数据实时处理的重要工具,开发者可以通过理解其核心概念、工作原理和最佳实践来有效地开发和应用Storm,从而解决实际问题并提高业务效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/773077.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复