


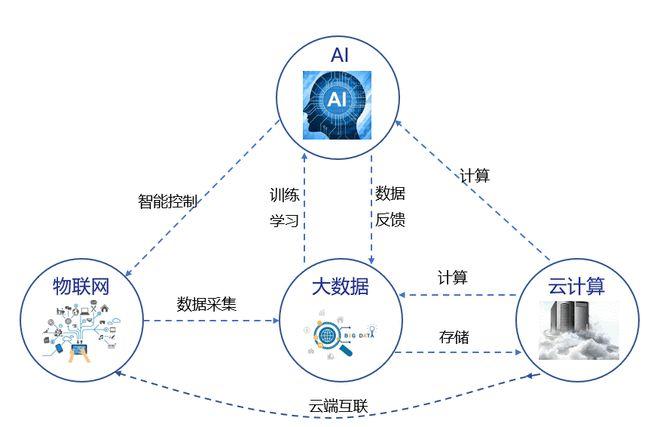
大数据时代,大型语言模型(Large Language Models,简称LLMs)已成为人工智能领域的重要突破,这类模型通过预训练和微调的方式,展现了卓越的学习能力和适应性,大模型的有效微调离不开合适的数据集,这不仅是模型精确性的保证,也是其应用广泛性的基础,下面将探讨大数据的利弊,并分析大模型微调对数据的要求。

利:
1、信息提取与知识发现:大数据分析能从海量信息中提取有价值的数据,促进新知识的发现。
2、业务决策支持:基于数据的决策更加客观和准确,有助于企业优化资源配置,提升运营效率。
3、客户洞察与个性化服务:通过分析用户行为和偏好,企业可以设计更加个性化的产品和服务。
4、趋势预测与风险管理:利用历史数据进行趋势分析,预测未来可能的变化,帮助企业及早做好风险控制。
弊:
1、隐私泄露风险:大规模数据收集和分析可能侵犯个人隐私,引发信息安全问题。
2、数据质量和准确性:数据的质量直接影响分析结果的可靠性,而数据错误、不完整或过时的问题普遍存在。
3、依赖性和取代性问题:过度依赖数据驱动的决策可能导致人为判断力的减弱,且在数据不足时难以做出决策。
4、复杂性和成本:大数据技术的应用和维护需要高昂的成本和专业技能,对于许多企业来说门槛较高。
大模型微调需要的数据有要求吗?
大模型微调过程中,数据的质量、相关性和多样性是至关重要的因素,以下是具体的数据要求:
1、质量要求:数据必须经过严格的清洗和预处理,确保无错误和噪声,以提高模型的准确性和应用效果。
2、格式统一:为了便于处理和分析,数据应为统一的格式,包括但不限于结构化数据、半结构化数据及非结构化数据。
3、代表性样本:用于微调的数据应具有足够的代表性,能够覆盖模型所需处理的各种场景和任务类型。
4、时效性:数据应是最新的,以反映最近的业务环境和用户需求,避免因数据过时而导致的模型偏差。
5、多样性:数据集应包含多样化的信息,以确保模型具有良好的泛化能力,能在多种情境下工作。
6、规模适中:虽然大规模的数据集能提供更丰富的信息,但过大的数据集会增加处理难度和成本,因此需根据实际需求确定合适的数据规模。
7、合规性:在使用数据时,必须遵守相关的法律法规,尊重用户隐私,确保数据处理的合法性。
8、血缘清晰:数据的来源、处理历程应当清晰记录,保证数据血统的透明度,便于追踪和管理。
大数据在带来巨大价值的同时,也伴随着一系列挑战和风险,大模型的微调对数据集提出了高质量、统一格式、代表性、时效性、多样性、合适规模、合规性和清晰血缘等要求,这些要求确保了模型能够在实际应用中达到最佳性能,同时也提示着数据工程在模型开发过程中的重要性,在享受由大数据技术带来便利的同时,人们也要正视其潜在的弊端,采取有效措施来规避风险,实现大数据与大型模型的和谐共生。
相关问答FAQs
问:如何评估数据集是否适合用于大模型微调?
答:可以从以下几个方面来评估数据集的适用性:首先检查数据质量,确认数据是否干净、无噪声;评估数据的代表性和多样性,看是否能覆盖模型所需面对的各类场景;确认数据的时效性,确保数据是最新的;查看数据的格式是否统一,以及是否有清晰的数据血缘。
问:如果数据集不够理想,有哪些方法可以改善?
答:若数据集不够理想,可以尝试以下几种方法进行改善:数据增强,通过技术手段增加数据的多样性;数据合成,人工生成缺少的数据样本;重新采样,选择更具代表性的数据子集;以及使用迁移学习,借鉴其他领域的数据特征来丰富当前数据集。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/772902.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复