


大数据和大容量数据库
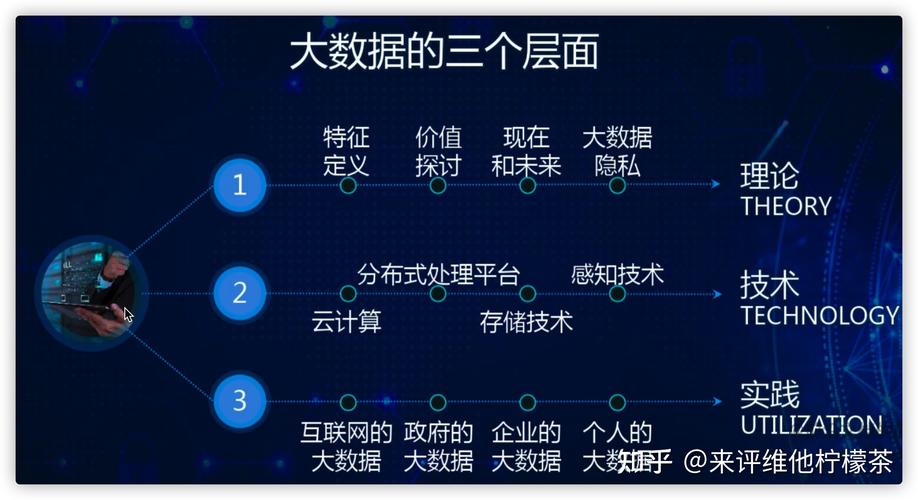

定义与区别
在当今数据驱动的时代,大数据和大容量数据库是信息技术领域中两个核心概念,它们虽然都与数据的存储和处理相关,但侧重点和应用背景有所不同。
大数据通常指的是无法用传统数据库工具进行捕获、管理、处理和分析的庞大而复杂的数据集,这些数据可以来自多种来源,包括社交媒体、传感器、交易记录等,大数据的特点可以用“五V”来概括:Volume(大量)、Velocity(高速)、Variety(多样性)、Veracity(真实性)和Value(价值)。
大容量数据库则是指设计用来存储、管理和检索大量数据的系统,这类数据库强调的是数据的一致性、可靠性和可访问性,它们通常用于支持事务处理,如银行交易、库存管理等。
技术架构
大数据技术栈
大数据的处理流程涉及数据的采集、存储、处理和分析,常见的大数据技术包括:
数据采集:如Apache Kafka
数据存储:如Hadoop Distributed File System (HDFS)、NoSQL数据库
数据处理:如Apache Hadoop MapReduce、Apache Spark
数据分析:如Apache Hive、Apache Pig
大容量数据库技术
大容量数据库通常采用的技术有:
关系型数据库管理系统(RDBMS):如MySQL、Oracle、Microsoft SQL Server
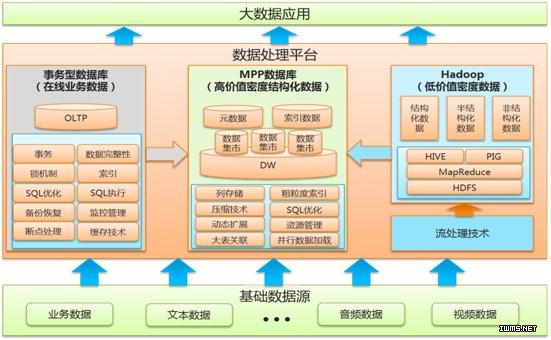
非关系型数据库(NoSQL):如MongoDB、Cassandra、DynamoDB
新型数据库:如Google Bigtable、Amazon DynamoDB
应用场景
大数据应用
商业智能:通过分析消费者行为、市场趋势等,为企业决策提供支持。
互联网搜索:搜索引擎使用大数据技术来索引网页并快速响应查询。
风险管理:金融机构利用大数据分析来评估和管理风险。
大容量数据库应用
在线事务处理(OLTP):如银行系统、电子商务平台的交易处理。
企业资源规划(ERP)系统:管理企业内部的资源和流程。
供应链管理:跟踪产品的生产、分销和销售过程。
性能考量
在设计大数据和大容量数据库系统时,性能是一个关键考量因素,这包括:
扩展性:系统能否随着数据量的增长而无缝扩展。
并发处理能力:系统能同时处理多少请求或任务。
容错能力:在硬件故障或网络问题发生时,系统能否继续运行。
数据一致性与完整性:确保数据的准确性和可靠性。
未来趋势
随着技术的发展,大数据和大容量数据库领域也在不断进化,云服务的普及使得数据存储和处理更加灵活和经济高效,人工智能和机器学习的应用也在推动数据处理能力的提升。
相关问答FAQs
Q1: 大数据和大数据技术有什么不同?
A1: 大数据指的是庞大且复杂的数据集本身,而大数据技术是指用于处理这些数据集的一系列技术和工具,简而言之,大数据是目标,大数据技术是实现这一目标的手段。
Q2: 如何选择合适的数据库系统?
A2: 选择合适的数据库系统需要考虑多个因素,包括数据的类型、规模、访问模式和业务需求,对于需要高速事务处理的场景,传统的关系型数据库可能更合适;而对于大规模、非结构化数据的存储和分析,则可能更适合使用NoSQL数据库或大数据技术,还需要考虑成本、易用性和技术支持等因素。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/772515.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复