


在Python中,正则表达式是一种强大的文本处理工具,它允许以灵活且高效的方式检索、替换、匹配和分割字符串,Python的re模块提供了Perl风格的正则表达式模式支持,使得可以在字符串中进行复杂的匹配和操作,下面将深入探讨Python中正则表达式的各种元素和用法:


1、基础匹配
字符匹配:最基本的正则表达式是字符匹配,可以直接匹配字符串中的字符。
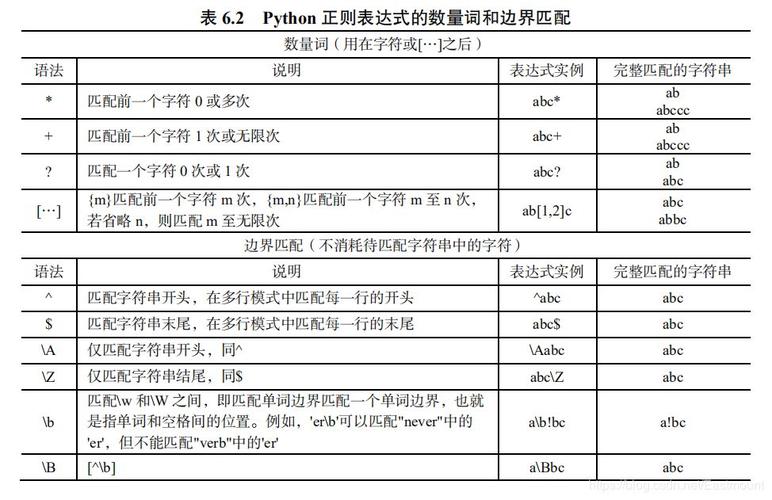
类字符:使用特定符号来表示字符类,例如d代表任意数字,w代表任意字母和数字等。
量词:如表示前一个元素的零次或多次出现,+表示一次或多次出现,?表示零次或一次出现,以及具体的次数可以使用大括号{}来指定。
2、预搜索
肯定顺序环视:(?=...)表示后面紧跟着匹配的内容。
否定顺序环视:(?!...)表示后面不是匹配的内容。
肯定逆序环视:(?<=...)表示当前位置前面是匹配的内容。
否定逆序环视:(?<!...)表示当前位置前面不是匹配的内容。
3、特殊字符
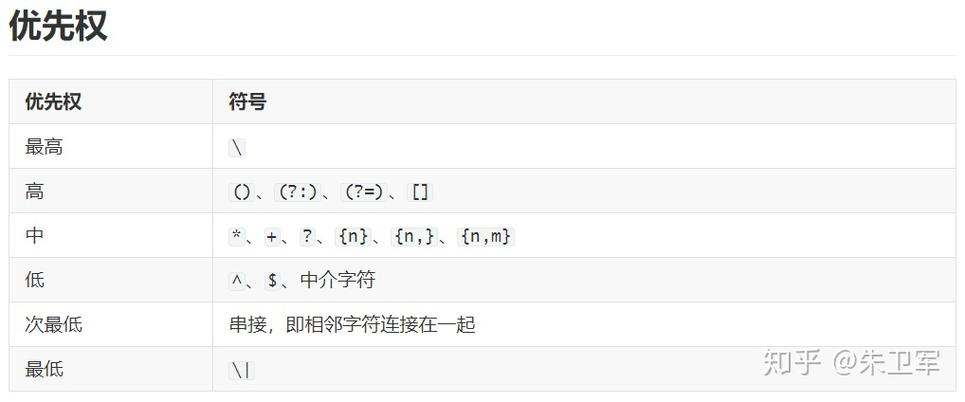
分组:使用圆括号()对正则表达式进行分组。
转义:由于Python字符串本身使用反斜杠进行转义,所以在正则表达式中需要使用两个反斜杠\或者使用原始字符串前缀r。
选择分支:使用管道符|表示多个可能的匹配选项。
非捕获组:使用(?:...)的形式可以定义一个不捕获的分组,即该分组匹配的文本不会保存供后续使用。
4、高级应用
条件表达式:允许根据前一个子表达式是否匹配来决定下一个子表达式。
递归匹配:正则表达式可以写作递归模式,以匹配嵌套的结构。
命名组:可以使用(?P<name>...)为组取名字,便于在后续的处理中引用。
Unicode支持:通过一些特定的标志(如re.UNICODE),可以让正则表达式支持Unicode字符属性。
5、标志作用
全局匹配:使用re.GLOBAL标志,使得正则表达式可以在整个字符串中查找所有匹配的位置,而不仅仅是第一个。
不区分大小写:使用re.IGNORECASE标志进行不区分大小写的匹配。
多行模式:使用re.MULTILINE标志,使得^和$特殊字符能够匹配每一行的开始和结束。
点号匹配:通常点号.不匹配换行符,使用re.DOTALL标志可以让点号匹配包括换行符在内的任何字符。
6、实用函数
搜索函数:re.search()用于在字符串中搜索模式,如果找到则返回一个匹配对象。
查找全部:re.findall()返回一个包含所有匹配项的列表。
替换子串:re.sub()函数用于替换字符串中与模式匹配的子串。
分割字符串:re.split()根据匹配的模式来分割字符串。
7、模式编译
编译优化:可以使用re.compile()函数预编译正则表达式,提高执行效率。
缓存编译:对于重复使用的正则表达式,编译后的对象可以被缓存重用。
模式对象方法:编译后的对象拥有自己的方法,如search(),findall()等。
8、匹配对象
获取信息:通过匹配对象可以获取诸如字符串是否匹配、匹配的索引和内容等信息。
访问:使用匹配对象的group()方法可以访问到具体的分组内容。
迭代匹配:匹配对象支持迭代,可以遍历所有的分组。
扩展切片语法:可以使用切片语法来访问匹配的特殊元素。
9、贪心与非贪心
贪心匹配:正则表达式默认是贪心匹配,会尽可能多地匹配字符。
非贪心匹配:通过在量词后面加上?来实现非贪心匹配,尽可能地匹配更少的字符。
10、特殊序列
字符类:使用方括号[]表示一个字符集合,可以匹配其中任意一个字符。
范围:在字符类中使用连字符表示字符范围,如[az]表示小写字母。
否定字符类:使用尖括号^作为方括号内的第一个字符,表示否定的字符类。
预定义字符类:如s表示空白字符,S表示非空白字符等。
Python的正则表达式由re模块提供支持,包含了丰富的功能和灵活的应用方法,从基本匹配到高级应用,正则表达式都是处理字符串的强大工具,了解和掌握Python正则表达式的各个部分,可以大幅提高字符串处理的效率和准确性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/767764.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复