


在探讨键值(KV)数据库和MapReduce如何结合用于更新键值对时,需要理解KV数据库的基本概念与MapReduce编程模型的工作原理,下面将详细解析KV数据库的特点、MapReduce如何处理键值对数据,以及这一过程中涉及的最新技术进展。


KV数据库简介
1、数据模型与存储结构
键值数据模型:KV数据库采用简单的键值数据模型,每个记录由一个唯一的键和对应的值组成。
存储结构多样化:可以采用哈希表、B+树等不同存储结构,每种结构都有其特定的应用场景和优势。
2、基本数据操作
CRUD操作:提供创建(Create)、读取(Read)、更新(Update)、删除(Delete)等基本操作,允许通过键进行数据的插入、查询、更新和删除。
批量操作和事务支持:部分KV数据库支持批量操作和事务,提高数据处理的效率和完整性。
3、分布式架构与数据一致性
分布式架构:为了处理大规模数据,许多KV数据库支持分布式架构,通过数据分片和复制提高系统性能和可靠性。
数据一致性机制:在分布式环境中,使用副本复制、分布式事务等机制来保持数据一致性。
4、应用场景
快速读写访问:KV数据库适用于需要快速读写访问的场景,如缓存系统、会话管理等。
非严格数据模型需求:适用于对数据模型没有严格要求的应用,强调数据的快速存取和查询。
MapReduce与键值对处理
1、MapReduce基本概念
数据处理框架:MapReduce是一个编程模型,用于大规模数据集(大于1TB)的并行运算。
键值对形式:MapReduce过程中,输入数据和输出数据都以键值对的形式出现。
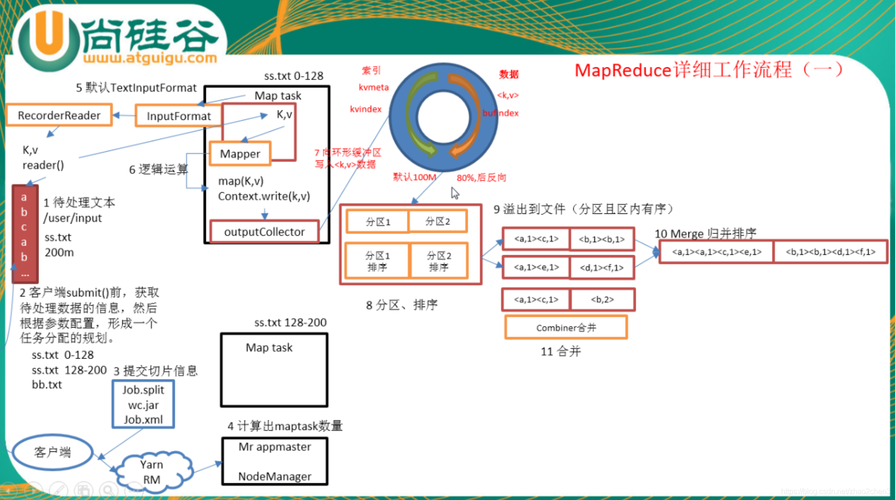
2、MapReduce执行流程
Map阶段:处理输入键值对,并产生一系列中间键值对。
Reduce阶段:处理具有相同键的所有值,并产生一组输出键值对。
3、键值对生成机制
InputSplit与RecordReader:数据首先被分割成InputSplit,然后通过RecordReader转换成键值对供Mapper处理。
Map和Reduce函数:Map函数处理输入键值对并发出键值对列表,Reduce函数则处理这些列表并发出最终的输出键值对。
4、Hadoop中键值对的生成依赖
Map输入与输出:Map阶段的输入默认以文本的行号为键,内容为值;输出则依赖于应用逻辑定义的键和值。
Reduce输入与输出:Reduce阶段的输入即为Map的输出,其输出则根据所需的结果定义。
最新技术进展
1、RocksDB与LSM树存储引擎
LSM树特点:RocksDB采用LSM树结构,通过在内存中暂存修改,定期写入磁盘,优化了写操作的性能。
高负载场景设计:RocksDB设计目标包括高效存取、高负载服务器性能提升,支持高效的查找和范围scan。
2、Redis 6.0的新特性
多IO线程:引入多IO线程,提升网络吞吐能力和整体处理性能。
ACL管理:增强了访问控制能力,提供细粒度的权限管理。
3、阿里云Redis企业级特性
性能与成本:Tair性能增强版提供卓越的性能特性,混合存储版则降低成本并提供超大规格的KV数据库选择。
安全性与管控功能:引入SSL加密提升安全性,半同步复制选项加强数据可靠性保障。
4、HotRing的创新设计
热点问题解决方案:HotRing通过动态识别并调整索引结构来应对热点访问问题,显著提升了KVS引擎的性能。
具体分析如何在MapReduce框架下更新KV数据库中的键值对,并结合上述提到的最新技术进展进行详细阐述。
更新KV数据库中的键值对
在MapReduce框架下,更新KV数据库中的键值对主要涉及到数据的读取、处理和写回三个步骤,在这个过程中,可以利用MapReduce的分布式计算能力,有效地处理和更新大规模的键值对数据,具体分析如下:
1、数据读取与Map阶段
InputFormat自定义:为了从KV数据库中读取数据,需要自定义InputFormat以适应数据库的特定格式和访问模式,这样可以确保数据按照期望的键值对形式被MapReduce处理。
数据分片与RecordReader:数据分片(InputSplit)确定了单个Mapper任务需要处理的数据量,通过定制RecordReader,可以将数据库中的数据转换为键值对,供Mapper使用,可以设计RecordReader直接从数据库的表中读取行,将行键作为键(key),行的内容作为值(value)。
2、数据处理与Reduce阶段
Map函数设计:Map函数接收数据库行转换为的键值对作为输入,执行必要的过滤和转换操作,在更新操作中,Map函数可能需要根据某些条件筛选出需要更新的记录。
Reduce函数设计:Reduce函数负责接收来自Map函数的键值对,并按照键(key)进行分组和聚合处理,在更新操作中,Reduce函数会实现实际的数据更新逻辑,比如修改值(value)或合并多个值。
3、写回KV数据库
Reduce输出与数据库写入:经过Reduce处理后的键值对需要写回到KV数据库中,这通常需要自定义OutputFormat来将结果写入到数据库中相应的位置,可以通过数据库的API或JDBC接口将结果集批量写入数据库。
事务与错误处理:在写回数据库的过程中,需要确保操作的原子性和一致性,如果更新操作涉及到复杂的数据校验或多表更新,可能需要利用数据库的事务支持来保证数据的完整性,应当处理可能出现的错误和异常,确保整个过程的健壮性。
4、优化与性能提升
数据本地化优化:配置MapReduce作业时,可以通过数据本地化优化来减少网络传输开销,提高处理速度,将计算任务调度到数据所在的节点上执行,可以减少数据传输时间。
Combiner使用:在Map阶段后和Reduce阶段前使用Combiner,可以在Map节点上先进行局部汇总,减少数据传输量,这对于更新操作特别有用,因为它可以显著减少需要在网络中传输的数据量,从而加快更新速度。
通过MapReduce框架更新KV数据库中的键值对需要综合考虑数据读取、处理、写回以及优化等多个方面,利用MapReduce强大的并行处理能力,结合KV数据库的高读写性能,可以实现高效的大规模数据更新操作,结合最新的技术进展,如RocksDB的LSM树结构、Redis 6.0的新特性以及HotRing的热点问题解决方案,可以进一步提升数据处理的性能和效率,在实际应用中,这些技术和方法可以帮助企业和开发者更好地管理和更新大规模的键值对数据,满足日益增长的数据处理需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/767382.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复