


mapred job list all 来列出所有正在运行的作业及其ID。,,2. 终止作业:, 使用命令 hadoop job kill 来杀死指定的作业,“ 是您在第一步中找到的作业ID。,,请确保您有足够的权限来执行这些操作,并且谨慎操作以避免影响其他重要作业。在配置和优化MapReduce作业时,了解如何设定基线并有效地杀死(终止)长时间运行或出现问题的作业是至关重要的,下面将详细介绍如何配置MapReduce作业基线以及如何管理这些作业。
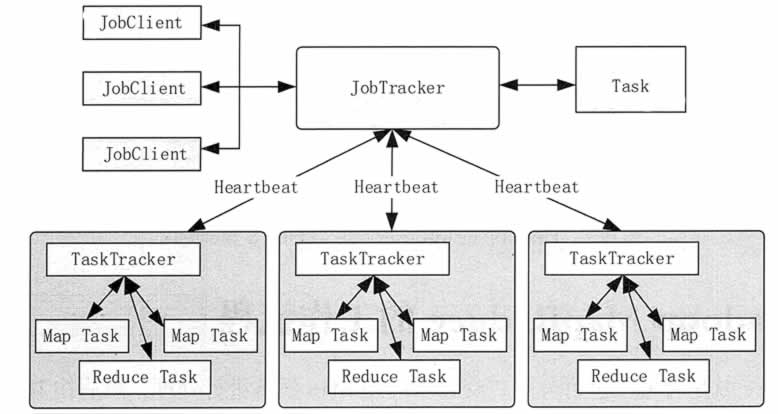

1. 理解MapReduce作业基线
MapReduce作业基线指的是作业性能的标准或期望水平,这包括作业的运行时间、资源使用情况(如CPU、内存和磁盘I/O)、数据处理速率等,确定基线有助于识别哪些作业表现不佳,需要优化或终止。
2. 监控和分析MapReduce作业
a. 使用Hadoop自带工具
MapReduce Web UI: Hadoop自带的Web界面可以查看作业的状态、进度、计数器等信息。
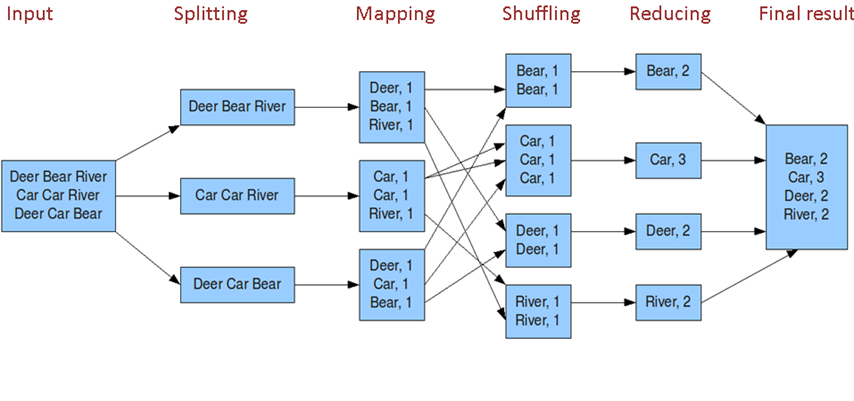
JobTracker和TaskTracker UIs: 提供作业和任务级别的细节。
b. 第三方监控工具
Ganglia: 用于监控Hadoop集群的资源使用情况。
Ambari: 一个基于Web的界面,用于配置、监控和管理Hadoop集群。
3. 配置作业参数
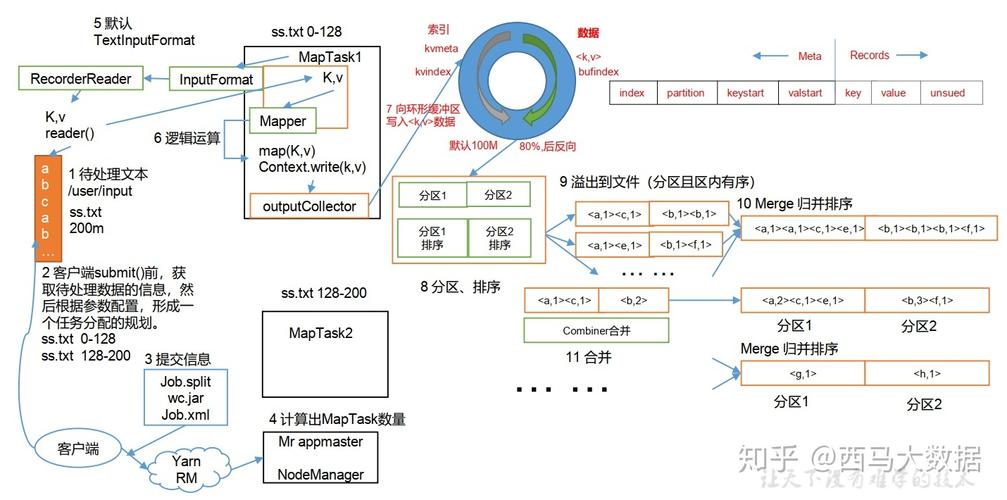
为了优化MapReduce作业,可以通过调整以下参数:
| 参数名称 | 推荐配置 |
| mapreduce.job.reduces | 根据数据大小和预期的处理能力设置Reduce任务的数量 |
| io.sort.factor | 控制Map输出的spill数量,影响磁盘I/O |
| mapreduce.map.memory.mb | Map任务的内存限制 |
| mapreduce.reduce.memory.mb | Reduce任务的内存限制 |
| mapreduce.map.cpu.vcores | Map任务的虚拟核心数 |
| mapreduce.reduce.cpu.vcores | Reduce任务的虚拟核心数 |
4. 杀死MapReduce作业
当某个作业不符合基线标准或出现异常时,可能需要终止它以释放资源。
a. 使用Hadoop命令
hadoop job list: 列出所有当前运行的作业。
hadoop job kill jobID: 通过作业ID杀死作业。
b. 通过YARN ResourceManager UI
可以在YARN ResourceManager的Web UI上选择作业并终止它。
5. 自动化监控和杀死作业
对于大型集群,手动监控和杀死作业可能不切实际,以下是一些自动化策略:
a. 定时检查和脚本
编写脚本定期检查作业状态,并根据预设的规则(如运行时间过长)自动杀死作业。
b. 集成告警系统
将监控工具与告警系统集成(如Email、SMS),在作业异常时发送通知。
6. 持续优化和学习
日志分析: 定期审查MapReduce作业日志,寻找性能瓶颈和异常。
更新和升级: Hadoop生态系统不断进化,及时更新可带来性能提升和新特性。
社区和文档: 积极参与Hadoop社区讨论,阅读官方文档和最佳实践。
归纳而言,配置和管理MapReduce作业是一个动态过程,需要根据作业的性能数据不断调整和优化,通过设定合理的基线,使用合适的工具进行监控,及时杀死异常作业,并持续学习和优化,可以显著提高MapReduce作业的效率和效果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/766401.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复