


偏倚机器学习
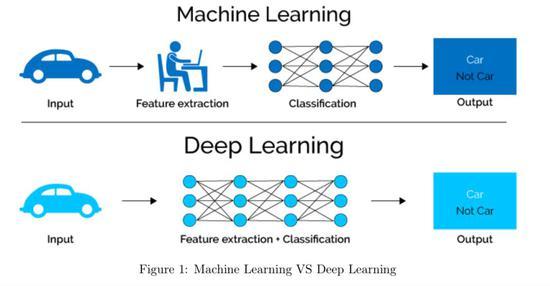

偏倚(Bias)在机器学习中指的是模型对训练数据的拟合不足,即模型无法完全捕捉数据的内在规律,这种误差来源于模型本身的简化假设或算法的局限性。
1. 偏倚与方差的概念
偏倚:模型的期望预测值与真实值之间的差异,这反映了模型在多次独立训练过程中,其平均预测值与真实值之间的系统性误差。
方差:模型在不同训练数据上预测结果的波动性,高方差意味着模型过于依赖训练数据,缺乏泛化能力。
2. 偏倚的来源
模型简化假设:为降低问题复杂度,模型可能采用简化的假设,导致无法完全表达数据特性。
算法局限性:选用的学习算法可能不适用于特定问题,限制了学习效果。
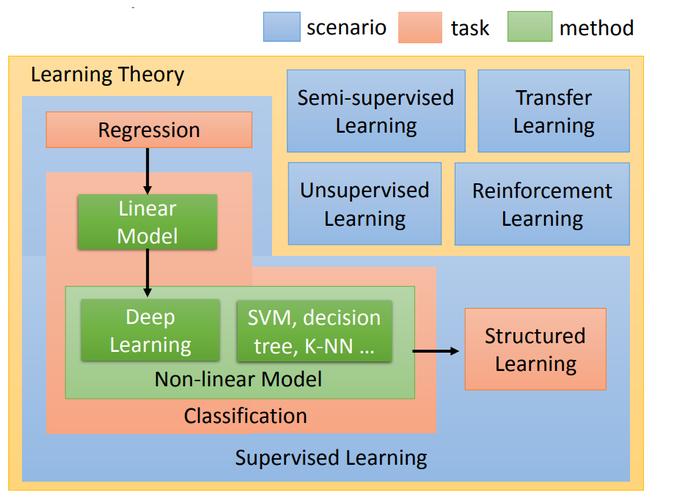
3. 影响及对策
欠拟合现象:偏倚高的模型通常表现为欠拟合,即在训练和测试数据上都表现不佳。
优化方法:选择更复杂的模型、增加特征数量或调整模型参数以减少偏倚。
机器学习端到端场景
端到端机器学习提供了一种从原始数据输入到最终决策输出的一站式解决方案,特别适用于深层神经网络。
1. 端到端学习的定义与优势
定义:一种将输入数据直接映射到输出结果,无需人工干预特征提取过程的学习方式。
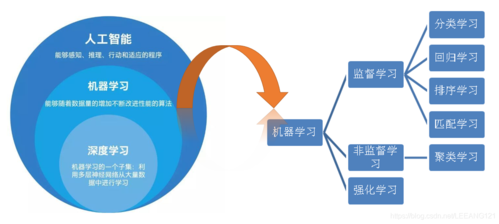
优势:自动化程度高,减少了人为设计特征的需要,尤其适合处理图像、语音等复杂数据类型。
2. 实施步骤
数据标注:确保有足够的标注数据支持模型的学习过程。
模型训练:选择合适的算法和框架进行模型训练,如使用CNN进行图像分类。
服务部署:将训练好的模型部署到实际应用场景,如通过API提供服务。
3. 应用领域
自动驾驶:利用端到端学习实现环境感知和决策制定。
自然语言处理:例如语音识别和机器翻译系统。
相关问答FAQs
Q1: 如何检测并减少机器学习中的偏倚?
A1: 可以通过交叉验证、引入更多特征或更换更复杂的模型来检测和减少偏倚。
Q2: 端到端学习有哪些挑战?
A2: 主要挑战包括需要大量标记数据、计算资源消耗大以及调试困难等。
理解并正确处理偏倚是提高机器学习模型准确性的关键,端到端学习作为一种高效的解决方案,在众多领域显示出强大的潜力和广阔的应用前景,通过持续的研究和实践,我们可以进一步优化这些技术,使其更好地服务于实际应用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/766064.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复