


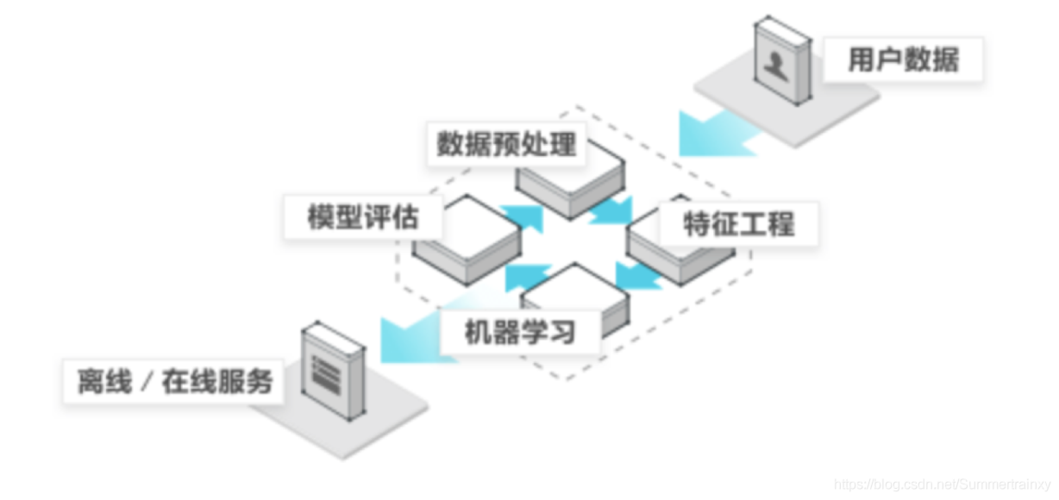
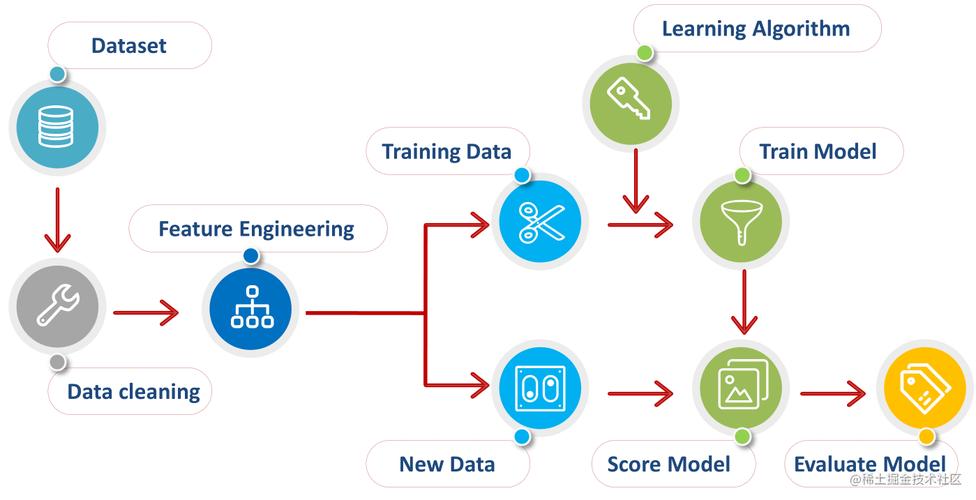
在当今的数据驱动时代,机器学习作为人工智能的一个核心分支,对于数据分析和预测建模起着至关重要的作用,Python凭借其强大的库支持和易用性,成为了实现机器学习算法的首选语言之一,本文将深入探讨Python中机器学习的端到端场景,从数据预处理到模型评估,全面介绍整个流程。

数据预处理
数据预处理是机器学习工作流程中的第一步,它直接影响到模型的性能和结果的可靠性,在Python中,我们通常使用Pandas库进行数据的加载、清洗和转换,数据清洗可能包括处理缺失值、去除重复记录和异常值处理等,为了适应机器学习模型的需要,通常还需要进行特征工程,包括特征选择、特征变换和特征缩放等步骤,Scikitlearn库提供了众多方便的工具类来执行这些操作。
选择模型
根据问题的类型(分类、回归或聚类),我们需要选择合适的机器学习模型,Python的Scikitlearn库提供了丰富的算法选择,如线性回归、决策树、支持向量机、K近邻(KNN)、朴素贝叶斯、随机森林等,线性回归适用于预测连续值的问题,而逻辑回归则更适用于二分类问题。
训练模型
选择了模型后,接下来就是使用训练数据集来训练模型,这一过程涉及到选择合适的训练算法(如梯度下降、随机梯度下降等),设置模型参数,以及使用fit方法来训练模型,在这个阶段,交叉验证是一种常用的技术,可以帮助我们评估模型在独立数据集上的表现,并避免过拟合问题。
模型评估
训练完成后,需要对模型的性能进行评估,评估指标根据问题类型而异,对于回归问题可能是均方误差(MSE)或决定系数(R^2),而对于分类问题则可能是准确率、召回率、F1分数或AUCROC曲线,Scikitlearn提供了model_selection模块中的多种评估函数,可以方便地进行模型性能的评估。
超参数调优
大多数机器学习算法都有一些可调节的超参数,这些参数在模型训练之前就需要设定,超参数调优是通过调整这些参数以提高模型性能的过程,在Python中,可以使用GridSearchCV或RandomizedSearchCV来进行系统地搜索最优参数组合。
部署模型
模型开发完成后,下一步是将模型部署到生产环境中,这可能涉及到将模型保存为文件(使用Scikitlearn的joblib库),然后在新的应用中加载模型来进行预测,可能需要开发API接口,以便不同的应用程序可以与模型交互。
持续监控与优化
部署后的模型需要持续监控其性能,因为随着时间的推移,模型的预测精度可能会下降(概念漂移),随着新数据的不断积累,定期重新训练模型也是必要的。
相关问答FAQs
Q1: 如何处理机器学习中的不平衡数据集?
Q2: 如何避免模型过拟合?
Python机器学习算法的端到端场景覆盖了从数据预处理到模型部署的全过程,通过正确选择和调整模型,以及采用合适的数据预处理和评估技术,可以在各种应用场景中实现高效、准确的预测模型。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/765368.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复