


正则化(Regularization)在机器学习和统计学中是一种非常重要的技术,它旨在防止模型在训练数据上过度拟合,从而提高模型对未见数据的泛化能力,下面将详细解析正则化技术:

1、正则化的基本概念
定义:正则化是一种通过引入额外参数或惩罚项到模型中,以减小模型在训练集上的过拟合风险的技术。
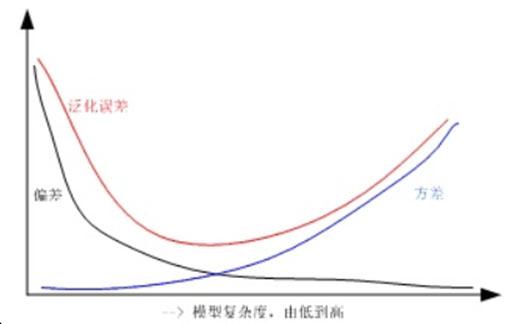
目的:控制模型复杂度,提高模型的泛化能力,确保模型能在未见数据上表现良好。
原理:通过对模型的参数或权重施加惩罚,限制其取值范围,避免模型因过度学习训练数据中的噪声而失去泛化能力。
2、正则化的作用和意义
防止过拟合:正则化帮助模型忽略训练数据中的噪声,关注数据的真实底层结构。
提高模型稳定性:通过限制参数的大小,减少模型对数据扰动的敏感性,增强其鲁棒性。
特征选择:某些正则化技术如L1正则化可以帮助进行特征选择,进一步简化模型。
3、正则化的工作原理
损失函数调整:正则化通过修改模型的损失函数,添加一个与模型权重相关的惩罚项来实现。
参数惩罚:常见的做法是对模型权重的L1范数或L2范数进行惩罚,从而限制权重的大小。
为了更全面地理解正则化技术,以下内容将详细介绍几种常见的正则化方法,并分析它们的应用场景、优势及劣势:
| 正则化方法 | 介绍 | 数学公式 | 应用场景 | 优势 | 劣势 | 具体例子 |
| | | | | | | |
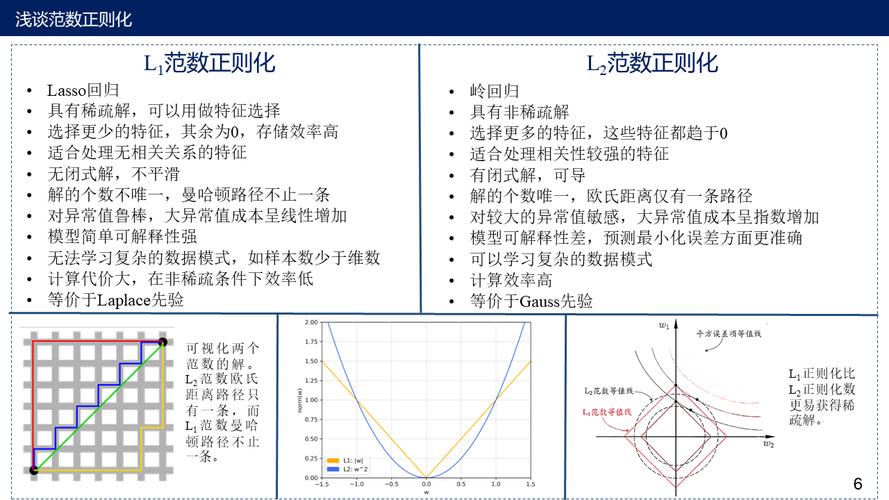
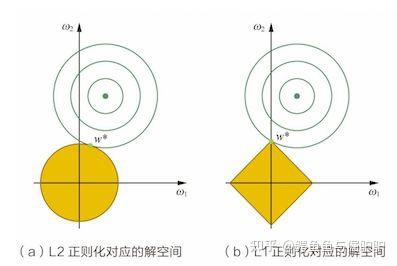
| L1正则化 | 推动稀疏解,有助于特征选择 | $L1 = lambda sum_{i} |w_i|$ | 特征数量极多时 | 产生稀疏权重矩阵,减少模型复杂度 | 可能导致部分有用信息丢失 | |
| L2正则化 | 倾向于避免权重过大,保持权重较小 | $L2 = lambda sum_{i} w_i^2$ | 需要模型权重均匀缩小时 | 有利于避免模型权重过大,提高模型稳定性 | 不产生稀疏权重,不进行特征选择 | |
| Dropout | 通过随机丢弃网络中的神经元来减少过拟合 | | 深度学习中神经网络训练 | 有效防止神经网络中的过拟合 | 可能需调整丢弃率以优化性能 | |
| 早停 | 在验证集性能开始下降时停止训练 | | 任何机器学习模型训练过程 | 简单实用,避免过拟合 | 需要分割训练集作为验证集 | |
| 数据扩充 | 通过生成合成数据增加数据多样性 | | 数据量不足或需要增强模型鲁棒性时 | 增强模型对数据变化的适应性 | 增加数据预处理的复杂性 | |
| 批量归一化 | 通过归一化加速训练并减少过拟合 | | 深度学习中加快训练速度时 | 加速训练过程,提高模型性能 | 增加了模型的计算负担 | |
正则化技术在机器学习和深度学习中扮演着重要角色,通过合理应用不同的正则化方法,可以显著提高模型的泛化能力和性能,选择合适的正则化方法取决于具体的应用场景和数据集特点,合理调整正则化参数是实现最佳性能的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/765144.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复