


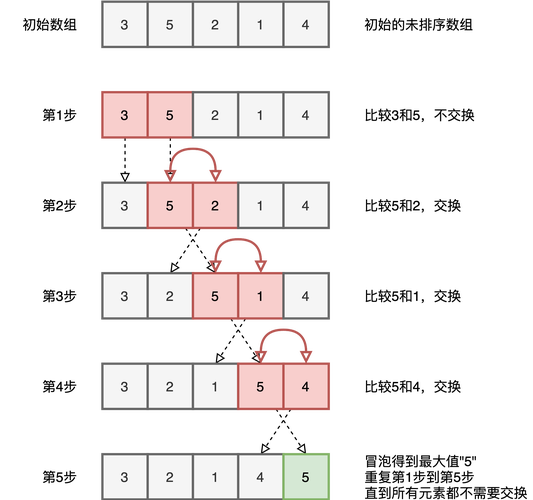

冒泡排序是一种简单的排序算法,它重复地遍历待排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,其基本思想是通过相邻元素之间的比较和交换,把每一对相邻元素中较小的元素“浮”到前面,较大的元素“沉”到后面。
Java中的冒泡排序实现步骤
1、代码实现
创建数组和临时变量: 初始化一个需要排序的整型数组和一个用于交换元素的临时变量int temp;
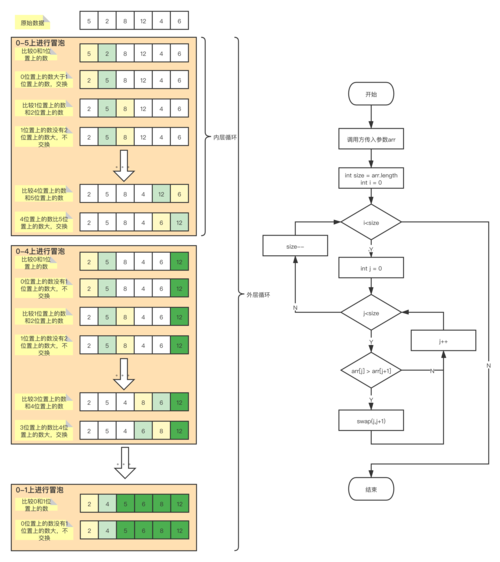
第一趟排序: 通过嵌套循环,外层循环控制排序趟数,内层循环控制每一趟的比较次数,如果前一个元素比后一个元素大,则交换它们的位置
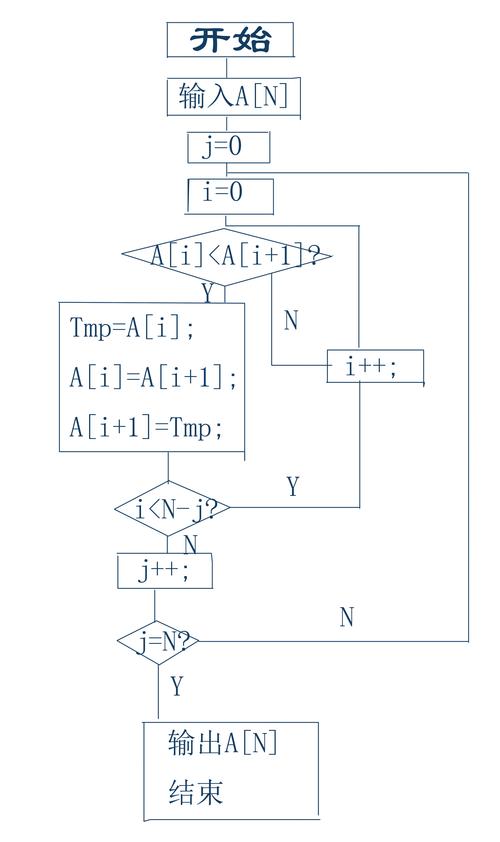
重复过程: 每次遍历都将最大的元素“冒泡”到数组的末尾,之后重复上述步骤,但不包括已排序的最大元素,直到整个数组排序完成
2、优化思路
标记交换: 引入一个布尔变量,如果在一趟遍历中没有发生任何交换,说明数组已经有序,可以提前结束排序
鸡尾酒排序: 这是冒泡排序的一种变体,它在每一趟遍历中,先从左到右进行冒泡排序,确保最大值被“冒”到右侧,然后再从右到左进行冒泡排序,确保最小值被“冒”到左侧
时间与空间复杂度分析
1、时间复杂度
最好情况: 输入序列已经有序,此时只需遍历一次,时间复杂度为$O(n)$
最坏情况: 输入序列完全逆序,此时需要遍历$n1$次,每次遍历都需要进行$ni$次比较和可能的交换($i$为当前遍历的次数),因此总的时间复杂度为$O(n^2)$
平均情况: 时间复杂度为$O(n^2)$
2、空间复杂度
空间复杂度: 冒泡排序只需要一个额外的空间来存储临时变量(用于交换),因此空间复杂度为$O(1)$
应用场景与优化建议
1、应用场景
小型数据集: 对于小型数据集,冒泡排序可能是一个合理的选择,因为其实现简单且易于编写
教学与学习: 冒泡排序是理解排序算法的良好起点,有助于初学者理解排序的基本概念
2、优化建议
提前终止: 如果在某一趟遍历中没有发生任何交换,说明数组已经排序完成,可以直接终止排序
减少无效比较: 每一次遍历都会使得至少一个元素到达其最终位置,因此在后续的遍历中可以忽略这些已经归位的元素
冒泡排序虽然在处理大规模数据集时效率较低,但它的简单性和易于理解使其成为学习排序算法的良好起点,在实际使用中,Java JDK提供了更高效的排序方法,推荐在项目中使用这些方法来提高性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/764818.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复