


多监督机器学习和机器学习端到端场景为当前AI实践中的重要概念,涉及模型从初始数据到最终应用的完整流程,多监督机器学习利用多种监控信号改进学习效率和性能,而端到端机器学习则强调从输入到输出的直接建模,优化整个系统的性能。
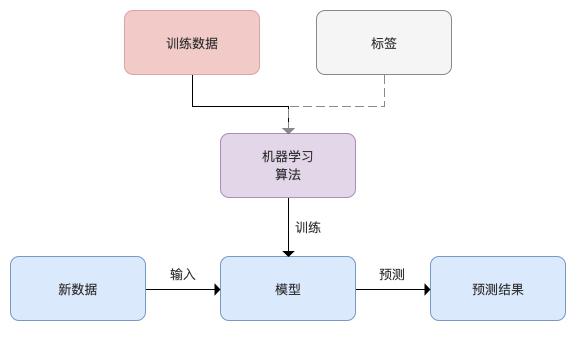

多监督机器学习
定义及原理
多监督机器学习是监督学习的一种扩展,它利用额外的监督信号,对模型进行训练,在传统的监督学习中,模型通常只接收一种类型的标签信息,在多监督学习中,模型能够同时从多个相关的监督信号中学习,如视频中的声音和图像,或是文本及其相应的翻译等,这种方法通过整合来自不同源或视角的数据,来增强模型的泛化能力和鲁棒性。
应用场景
多监督学习适用于需要综合多种数据类型的复杂场景,如多媒体信息处理、多语言文本分析、生物信息学中的基因表达数据结合临床数据的研究等,在自动驾驶车辆的开发中,车载系统需同时解析路面情况、交通标志以及周围车辆的动作等多种信息,以确保行车安全。
技术挑战
数据融合:如何有效地整合来自不同源的信息,使模型能从中学到有用的特征,而不至于引入噪声。
模型设计:设计能够处理多源信息的神经网络结构,确保各类信息均能得到合理处理。
训练效率:多监督学习任务往往需要更多的计算资源,如何提高训练效率与模型性能,是一个重要的研究方向。
机器学习端到端场景
定义及原理
端到端机器学习是指将整个数据处理流程纳入一个统一的模型中直接从输入到输出进行学习,无需分步骤单独优化,这种方法常用于深度学习模型,如卷积神经网络(CNN)在图像识别中的应用,端到端的学习可以自动发现表征数据的最佳方式,并减少手工特征工程的需要。
应用场景
典型的应用场景包括语音识别系统、自动机器翻译以及图像的风格转换等,在自动驾驶系统中,端到端的方法可以直接从传感器输入(如摄像头捕获的图像)预测驾驶操作,如方向盘转角,而无需人工介入识别道路边界或车辆。
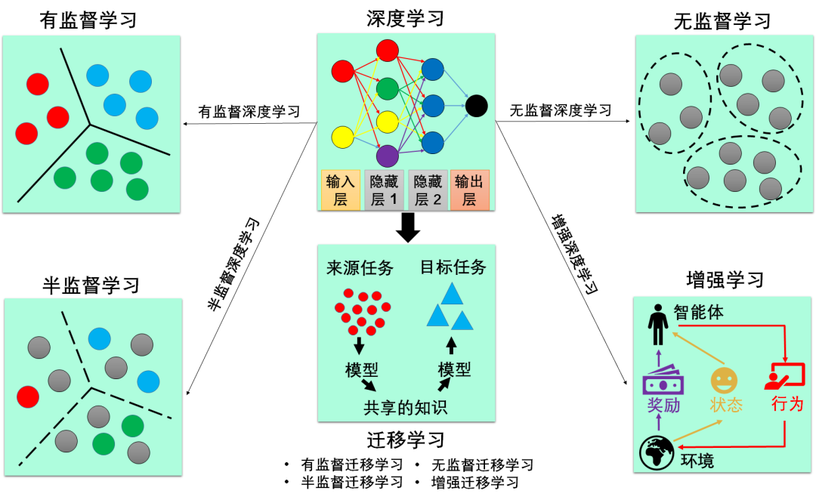
技术挑战
模型复杂度:端到端的模型往往参数众多,结构复杂,这可能导致过拟合问题。
可解释性:由于整个流程被黑箱化处理,模型的决策过程难以解释和调试。
数据依赖性:端到端学习对数据的依赖极大,数据质量高低直接影响模型效果。
端到端学习和多监督学习各有其优势和局限,选择适当的学习方法应根据具体应用场景和需求来决定,在数据丰富且需要快速迭代的场景下,端到端学习可能更为合适;而在需要精确控制和高度可靠性的应用中,多监督学习可以提供更优的性能。
相关问答FAQs
Q1: 多监督学习和多任务学习有什么区别?
A1: 多监督学习通常指的是利用额外的监督信号来增强模型的训练,这些信号来源于相同任务的不同视角或不同性质的数据,而多任务学习则是同时解决多个相关任务,通过共享表示或特征来提升所有任务的学习效果,两者都利用额外的信息来提升学习性能,但侧重点和应用的具体方式有所不同。
Q2: 如何评估一个端到端学习系统的性能?
A2: 端到端学习系统的性能可以通过多种指标来评估,具体取决于应用的需求,常见的评估指标包括准确率、召回率、F1分数等,针对特定应用还可能包括延迟时间、响应速度、资源消耗等实际操作指标,评估时还应注意检查系统的鲁棒性和稳定性,确保其在面对真实世界数据时的表现。
通过探讨多监督机器学习和机器学习端到端场景的原理与应用,我们可以看到现代AI技术在处理复杂数据和实现自动化决策中的潜力与挑战,理解这些方法的核心原理和适用场景,有助于我们更好地设计和实施AI解决方案,推动人工智能技术的发展与应用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/764407.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复