


Kappa系数是由Cohen在1960年提出,用于衡量两个或多个观察者对同一对象进行分类时的一致性程度,而皮尔森相关系数则是一种用于度量连续变量之间线性关系强度的统计指标,两者虽然都用于评价一致性或相关性,但应用场景和计算方法有所不同。

Kappa系数的计算公式为 ( kappa = frac{p_o p_e}{1 p_e} ),( p_o ) 表示观察一致性,即对角线上的元素之和与整个矩阵元素之和的比值;( p_e ) 表示随机一致性,可以通过求各行各列总和的乘积再除以总数平方的方式得到,具体数值解释如下:
| Kappa值 | 一致性程度 |
| 1 | 完全不一致 |
| 0 | 偶然一致 |
| 0.00.2 | 极低的一致性(slight) |
| 0.210.40 | 一般的一致性(fair) |
| 0.410.60 | 中等的一致性(moderate) |
| 0.610.80 | 高度的一致性(substantial) |
| 0.811 | 几乎完全一致(almost perfect) |
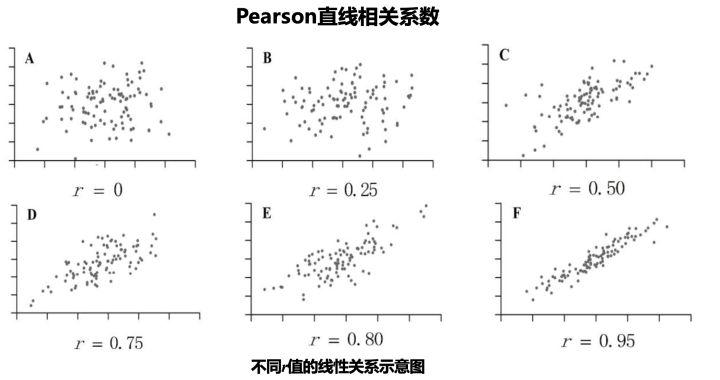
皮尔森相关系数的计算公式为 ( r = frac{sum (x_i bar{x})(y_i bar{y})}{sqrt{sum (x_i bar{x})^2 sum (y_i bar{y})^2}} ),( x_i ) 和 ( y_i ) 是两个变量的观测值,( bar{x} ) 和 ( bar{y} ) 是它们的平均值,该系数取值范围从1到1,1表示完全负相关,1表示完全正相关,0表示无关。
以下是对两种系数在不同方面的应用及意义的综合分析:
1、应用场景
Kappa系数:主要用于分类任务中评估两个观察者之间的一致性,比如医疗诊断中的评分一致性检验。
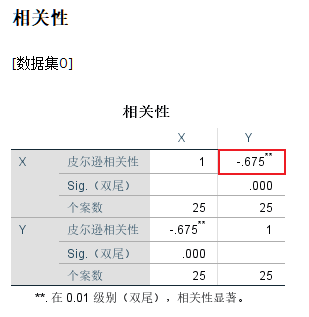
皮尔森相关系数:用于衡量两个连续变量之间的线性相关程度,例如用户兴趣相似度分析或预测值与真实值之间的相关性。
2、计算方法
Kappa系数:基于混淆矩阵,考虑实际一致和随机一致的情况。
皮尔森相关系数:基于协方差和标准差的比值,衡量变量间的线性关系强度。
3、取值范围
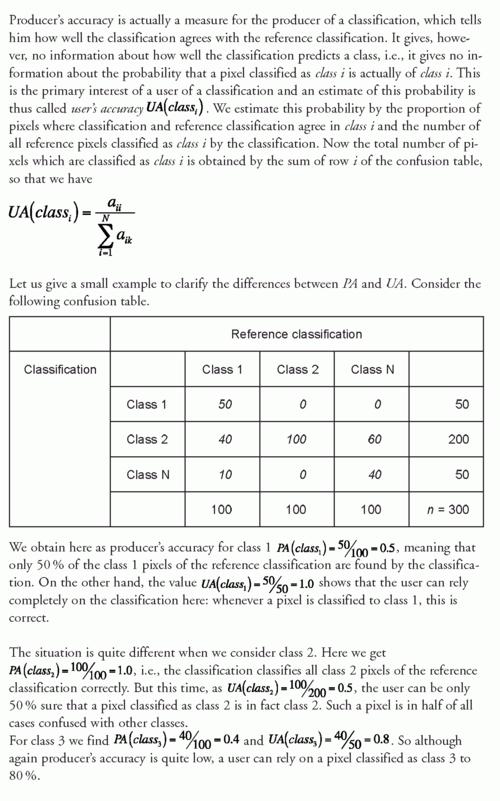
Kappa系数:介于1到1之间,不同区间段代表不同的一致性水平。
皮尔森相关系数:也在1到1之间,但解释的是相关性的方向和强度。
4、主要优势
Kappa系数:能够校正偶然发生的一致性,提供更准确的评估结果。
皮尔森相关系数:适用于连续变量并且能反映线性关系的强弱。
5、面临挑战
Kappa系数:受类别分布影响,二分类偏向以及对称性要求可能限制其应用。
皮尔森相关系数:假设数据呈正态分布,且只能反映线性关系,对于非线性关系无法准确度量。
通过对比分析,可以看到Kappa系数和皮尔森相关系数各有其适用的场景和优缺点,选择哪种系数取决于具体的研究需求和数据类型。
Kappa系数和皮尔森相关系数作为统计学中重要的一致性和相关性评价指标,各自有其独特的计算方法和应用场景,合理选择和运用这些系数,可以更准确地评估数据间的关系,从而为研究和决策提供有力支持。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/763963.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复