

Hive和普通关系数据库在存储系统、查询语言以及数据处理规模等方面存在明显的区别,具体分析如下:
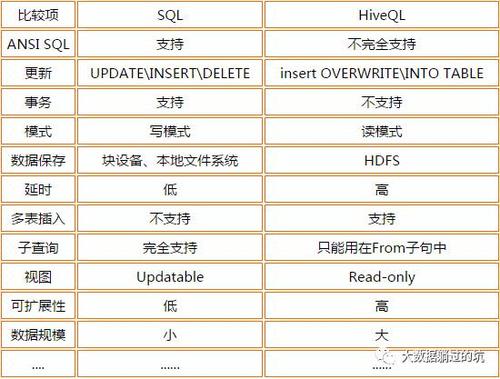
1、存储系统
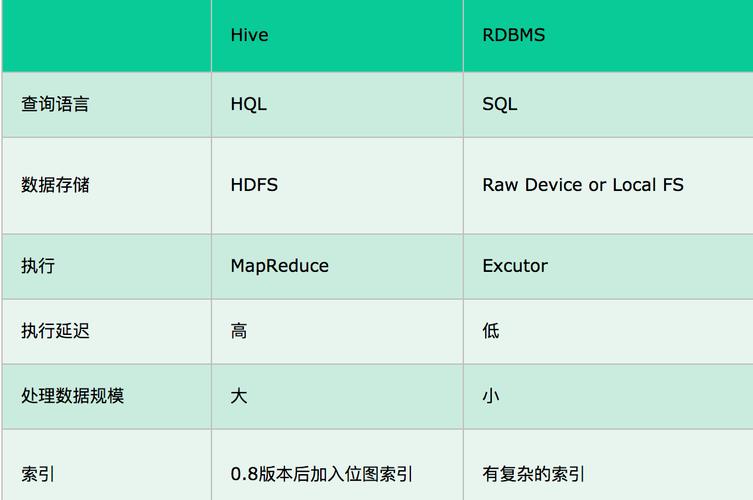
Hive:使用Hadoop的HDFS(Hadoop分布式文件系统)作为其存储系统,HDFS具有高容错性和可扩展性,适用于存储海量数据。
普通数据库:通常存储在服务器本地的文件系统中,这些文件系统如EXT3、NTFS等,并非专门为大规模数据分布设计。
2、查询语言
Hive:使用一种类似于SQL的查询语言称为HiveQL,虽然外表类似,但HiveQL的实现是基于Hadoop的MapReduce计算模型,这与传统的SQL在执行方式上有本质的不同。
普通数据库:使用标准的SQL(结构化查询语言),这是一种广泛使用于关系型数据库中的查询语言,用于管理与操作数据。
3、数据处理规模
Hive:专为处理大规模数据而设计,能处理PB级别数据,并且对此进行了优化。
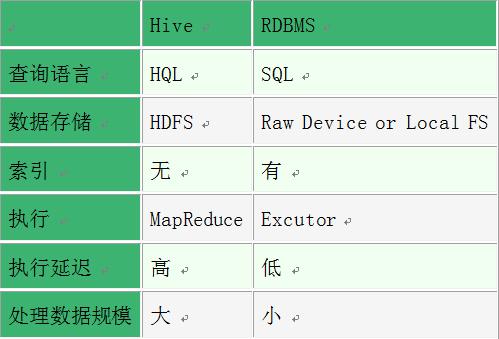
普通数据库:通常适合于处理较小规模的结构化数据,对于超大规模数据处理则可能不太适合。
4、实时性
Hive:不适用于实时数据处理,因为其查询通常需要转换为MapReduce任务,执行速度较慢。
普通数据库:支持实时事务处理,响应速度快,适合于需要快速读写的应用场景。
5、数据格式
Hive:没有定义专门的数据格式,用户可以根据需求指定不同格式,这包括列分隔符、行分隔符以及读取文件数据的方法,这种灵活性允许Hive处理各种形式的数据。
普通数据库:通常有固定或预设的数据格式,这对于特定类型的数据存储和快速操作有利,但在灵活性上可能不如Hive。
6、计算模型
Hive:使用的计算模型完全基于Hadoop的MapReduce,这是一种非常适合大规模数据集并行处理的模型。
普通数据库:拥有自己设计的计算模型,这些模型通常针对实时查询和事务进行了优化,而非批量数据处理。
Hive作为一个构建在Hadoop之上的数据仓库工具,专门针对大规模离线数据分析而设计,提供了高度的灵活性和可扩展性,相比之下,传统关系型数据库更擅长于处理实时事务和较小规模的数据,提供更快的数据访问和操作,根据具体的应用需求和数据特性,选择合适的工具非常关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/762073.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复