


【爬虫系统架构】
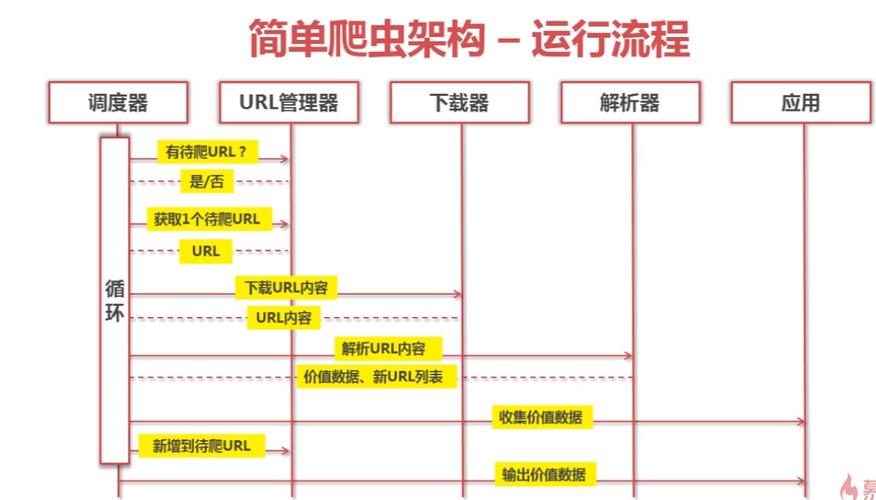

在网络数据抓取领域,爬虫系统架构的设计关乎着信息获取的效率与稳定性,一个高效的爬虫系统不仅可以提高数据抓取的速度,而且可以保证数据的完整性和系统的健壮性,以下是对爬虫系统架构的综合介绍,包括核心组件和设计考虑因素。
1、爬虫框架选择
Scrapy框架:Scrapy是一个使用Python编写的开源爬虫框架,它提供了强大的功能和良好的扩展性,Scrapy内置了URL管理和调度机制,支持多种数据存储后端,并允许用户通过中间件系统自定义和扩展爬虫行为。
分布式爬虫:分布式爬虫涉及多台机器同时处理多个URL,这需要解决的任务分配、机器协调以及异常处理等问题,可以通过使用如celery等分布式任务调度工具来达成高效数据处理。
2、核心组件构成
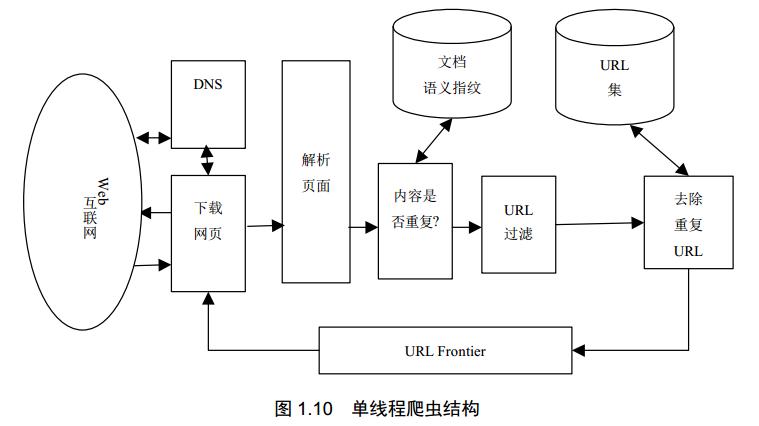
URL管理器:负责URL的去重、队列管理和调度,确保每个URL被正确处理,并避免重复爬取。
网页下载器:该模块用于从指定的URL下载网页内容,通常需要处理网络异常、设置代理和用户代理等任务。
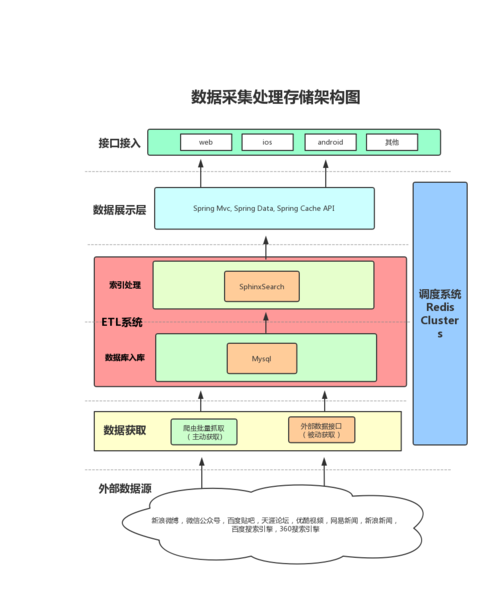
网页解析器:解析下载的网页内容,从中提取出有价值的数据,这可能涉及到HTML解析、文本抽取等功能。
数据存储器:将抓取的数据存储到文件系统、数据库或其他存储系统中,这要求数据格式转换和数据持久化的能力。
3、系统设计考虑
可伸缩性:分布式爬虫系统应设计为易于添加或减少资源,以应对不同规模的爬取任务。
错误处理与恢复:系统应能自动处理网络请求失败、数据解析错误等异常情况,并在出现问题时提供恢复机制。
反爬虫策略应对:设计爬虫时需要考虑应对目标网站可能采取的各种反爬虫措施,如IP封禁、登录验证等。
法律与伦理:爬虫设计需遵守法律法规,尊重网站的robots.txt规则,不侵犯版权和隐私权。
4、技术选型与实现
异步处理:异步爬虫可以提升系统处理速度,减少等待时间,适合处理大量的并发请求。
面向接口的编码:推荐使用面向接口的编程技术,增加系统的灵活性和可维护性。
代码组织:良好的代码组织能使爬虫系统更加清晰,便于后期维护和升级,比如采用MVC等设计模式。
5、性能优化
缓存机制:引入缓存可以减少重复的网络请求,提高爬虫效率。
动态调度:根据响应时间、网站负载等情况动态调整爬取频率和并发数,防止因过度请求导致的网站访问问题。
资源分配:合理分配系统资源,例如使用负载均衡技术分散请求压力,确保系统稳定运行。
爬虫系统架构的设计是一个综合性工程,需要考虑到框架选择、核心组件配置、系统设计和技术实现等多个方面,一个优秀的爬虫系统不仅能够高效地抓取数据,还能在出现异常时保持稳定运行,并具备良好的扩展性和适应性。
通过合理的架构设计和技术选型,爬虫系统可以在遵守法律和道德的前提下,有效地收集和处理网络信息,服务于数据分析、市场调研等多种业务场景。
FAQs
1. 如何选择合适的爬虫框架?
回答:
选择合适的爬虫框架应考虑以下几个因素:
项目需求:首先明确你的项目需求,包括数据量、数据类型、爬取频率等。
框架特性:了解不同框架的特性,如Scrapy适合中等规模和复杂度的项目,而简单项目可能只需基本的http请求库如requests。
社区和文档:一个活跃的社区和详尽的文档可以帮助你快速解决问题,学习新知识。
可扩展性:考虑框架是否支持插件或中间件,能否容易地添加新功能或集成其他服务。
性能考量:根据项目的性能需求,评估框架是否能处理高并发请求,以及其资源消耗情况。
2. 如何处理反爬虫机制?
回答:
处理反爬虫机制可以采取以下几种方法:
遵守规则:遵循目标网站的robots.txt协议,确保合法合规地进行数据抓取。
用户代理和IP伪装:通过更改用户代理和使用代理IP来模拟正常用户访问,减少被封锁的风险。
间隔抓取:设置合理的抓取间隔时间,避免频繁请求引起网站的反爬虫机制。
验证码处理:对于有验证码的网站,可以使用OCR技术识别或第三方验证码识别服务来解决。
分布式爬取:分布式爬取可以分散请求,降低单一IP的压力,减少被封禁的可能性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/761845.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复