


朴素字符匹配通常指在文本处理中,通过简单的字符串扫描匹配方法来识别单词或短语,而朴素贝叶斯分类是一种基于概率的分类方法,它的核心是应用贝叶斯定理,并在假设特征之间相互独立的前提下,进行类别的判断,下面将详细介绍朴素字符匹配和朴素贝叶斯分类的基本概念、特点和应用。

朴素字符匹配:
朴素字符匹配算法主要基于字符串扫描和字典匹配的原理,这种分词方法主要包括以下几种匹配规则:
1、正向最大匹配:从句子的开头开始,尽可能取最长的词进行匹配。
2、逆向最大匹配:从句子的结尾开始,尽可能取最长的词进行匹配。
3、长词优先:优先匹配长度更长的词。
该算法的优点在于简单易实现,只需根据预设的字典进行模式匹配即可,其缺点也同样明显,由于没有考虑词义和上下文,对歧义词的处理效果往往不佳。
朴素贝叶斯分类:
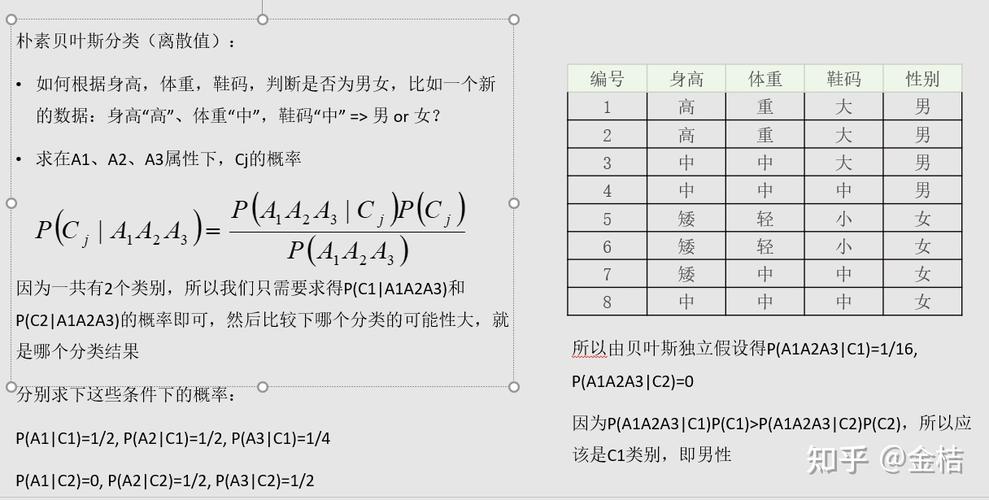
朴素贝叶斯分类器是基于贝叶斯定理的一种分类方法,贝叶斯定理是一个描述条件概率关系的方程式,可以表示为 P(L | features),即给定观察特征下求得标签的概率,朴素贝叶斯分类器的主要特点是假设各特征之间相互独立,这使得模型简化,计算效率高,但同时也可能限制了模型的准确性。
朴素贝叶斯分类器的几种常见类型包括:
1、高斯贝叶斯分类器:假设数据服从高斯分布。
2、多项式贝叶斯分类器:适用于计数数据,如文本分类中的词频统计。
3、伯努利贝叶斯分类器:适用于布尔值数据,如文本中是否出现某词。
朴素贝叶斯分类器因其简单和效率,在文本分类、垃圾邮件检测等领域得到了广泛应用,尽管其“朴素”假设在现实复杂数据环境中可能不总是成立,但在实践中依然表现出了良好的性能。
相关应用:
信息检索: 在搜索引擎中,利用朴素字符匹配对用户查询与索引词汇进行匹配,返回相关结果。
文本分析: 在文本预处理阶段,使用朴素字符匹配技术帮助识别和提取关键词汇。
情感分析: 朴素贝叶斯分类器用于分析社交媒体、产品评论等文本的情感倾向。
垃圾邮件检测: 朴素贝叶斯分类器被广泛用于识别和过滤垃圾邮件。
优缺点分析:
朴素字符匹配算法的主要优点在于其高效且易于实现,但其缺点是无法处理语义层面的歧义,可能导致分词准确性降低,而朴素贝叶斯分类器则以其简单和在特定条件下的良好性能著称,尽管其独立性假设可能会影响模型的泛化能力。
朴素字符匹配和朴素贝叶斯分类在文本处理和机器学习领域有着广泛的应用,虽然它们各自有局限,但在适当的应用场景下,这些方法仍然能够提供有效、高效的解决方案。
FAQs:
Q1: 朴素贝叶斯分类器的独立性假设是什么?
A1: 朴素贝叶斯分类器的独立性假设是指在分类任务中,假设各个特征之间是完全独立的,互不影响,这意味着在计算某个标签的条件概率时,可以简单地将各个特征对该标签贡献的概率相乘得到联合概率。
Q2: 如何提高朴素字符匹配算法对歧义词的处理能力?
A2: 要提高对歧义词的处理能力,可以通过引入更高级的语境分析和理解机制,如使用基于统计和机器学习的分词方法(例如隐马尔科夫模型或条件随机场),这些方法能够更好地考虑词义和上下文信息,从而提高分词的准确性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/761508.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复