


Avro和Parquet是大数据工程中常见的两种数据存储格式,它们在系统设计中可能同时被使用,掌握它们之间的转换技术是至关重要的,以下将深入探讨如何将Avro数据转换为Parquet格式的步骤和考虑因素:
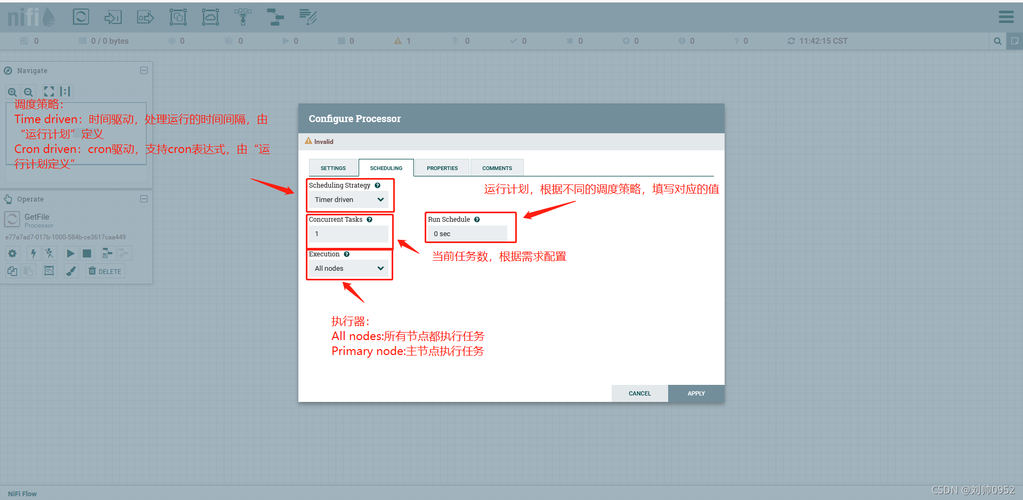

1、了解Avro和Parquet数据格式
Avro数据格式:Avro是一种行式存储格式,适合事务性工作负载,主要用于大量写入操作,它通过JSON格式定义Schema,支持复杂的数据类型,如arrays、枚举类型等,并且可以对数据进行压缩以节省空间。
Parquet数据格式:Parquet是一种列式存储格式,优化了读取繁重的分析工作负载,它支持多种编程语言,如Java、Python等,并且具有高效的压缩和编码方案,能够显著减少磁盘I/O开销,提高查询性能。
2、确定转换工具和语言环境
选择编程语言:根据搜索结果,Java是一个常用的编程语言选项,用于处理Avro到Parquet的数据转换,Java拥有强大的生态系统和丰富的库支持,使得这一过程相对简单且高效。
选择转换工具:可以选择Apache Parquet和Apache Avro提供的官方库,这些库提供了丰富的API和方法集,来读取、写入和转换数据文件。
3、设置合适的开发环境
搭建Java开发环境:需要确保Java环境已经正确安装,并配置好了必要的环境变量,如JAVA_HOME。
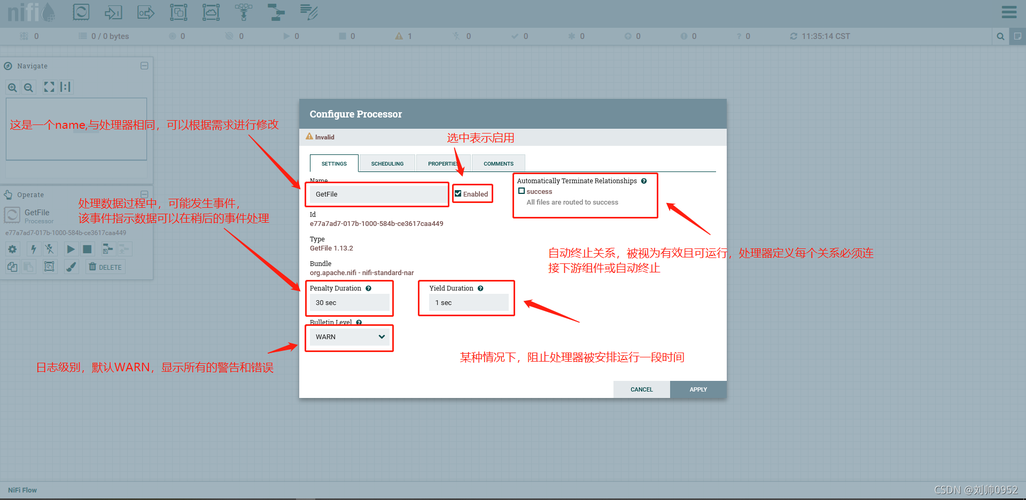
引入必要的依赖库:利用Maven或Gradle等构建工具,引入hadoopcore和parquetavro等相关依赖,以便在转换过程中使用。
4、准备数据和Schema
准备Avro数据文件:确保你有一个有效的Avro数据文件,该文件应该包含你想要转换的数据内容。
定义Avro和Parquet Schema:在转换之前,你需要定义Avro数据的Schema,同时也要为Parquet准备一个对应的Schema,因为Parquet在写入时需要Schema信息。
5、编写转换代码
读取Avro数据:使用Apache Avro库中的API读取Avro格式的数据文件。
转换为Parquet格式:将读取到的Avro数据使用Apache Parquet库提供的API转换成Parquet格式,在这一过程中可能需要处理LogicalTypes等特殊类型。
保存Parquet文件:将转换后的Parquet数据保存为文件或者直接存储在内存中,以便后续使用。
6、测试与验证
测试转换过程:确保转换过程中没有出现异常,并且转换后的数据符合预期。
校验数据完整性:可以通过比较转换前后的数据记录数、字段值等来验证数据的完整性和准确性。
检查Schema和元数据:检查生成的Parquet文件的Schema和元数据是否正确反映了原始Avro数据的结构。
在进行以上技术操作的同时,还需要考虑一些其他的因素:
性能优化:考虑到转换可能在大规模数据集上执行,因此应当关注转换的性能表现,比如是否有必要采用并行处理等策略。
兼容性维护:随着Avro和Parquet规范的更新,应确保转换方案能够兼容新的版本。
异常处理:在转换过程中可能会遇到异常情况,例如数据损坏、Schema不匹配等问题,应有相应的错误处理机制。
从Avro转换为Parquet格式涉及对两种数据存储格式的理解、适当的工具和语言选择、环境配置、数据和Schema的准备、编码实现以及最终的测试与验证,每一个步骤都需要谨慎处理,以确保数据的准确性和完整性,还需要考虑到性能优化、兼容性维护以及异常处理等方面,确保转换过程的平稳和高效。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/761186.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复