


根据提供的内容,生成的摘要如下:,,这是一个关于爬虫代码示例的请求。用户希望获得一个代码示例,以便了解如何编写爬虫程序。
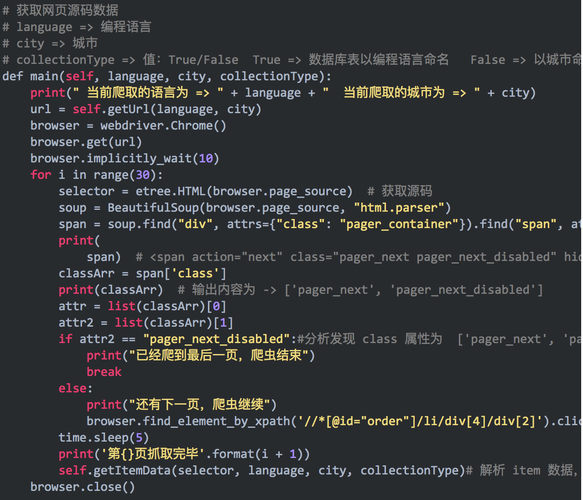
使用Python的BeautifulSoup和requests库抓取网页数据

(图片来源网络,侵删)
1. 环境准备
确保已经安装了Python以及必要的库,如果没有安装,可以使用以下命令进行安装:
pip install beautifulsoup4 requests
2. 导入库
在编写爬虫代码之前,需要先导入所需的库。
from bs4 import BeautifulSoup import requests
3. 请求网页
使用requests.get()方法请求目标网页,并获取响应内容。
url = 'https://example.com' response = requests.get(url) html_content = response.text
4. 解析HTML
(图片来源网络,侵删)
使用BeautifulSoup解析HTML内容。
soup = BeautifulSoup(html_content, 'html.parser')
5. 提取数据
根据HTML结构,使用BeautifulSoup的方法提取所需数据,提取所有的链接:
links = soup.find_all('a')
for link in links:
print(link.get('href')) 6. 保存数据
将提取的数据保存到文件或数据库中。
with open('output.txt', 'w') as f:
for link in links:
f.write(link.get('href') + '
') 7. 异常处理
在爬虫过程中可能会遇到各种异常,如网络问题、解析错误等,需要进行异常处理。

(图片来源网络,侵删)
try:
response = requests.get(url)
response.raise_for_status()
except requests.RequestException as e:
print(e) 8. 反爬虫机制应对
一些网站可能会有反爬虫机制,如设置UserAgent、使用代理等。
headers = {
'UserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers) 9. 遵守Robots协议
在爬取网站数据前,应查看网站的Robots协议,避免爬取不允许爬取的页面。
robots_url = 'https://example.com/robots.txt' response = requests.get(robots_url) print(response.text)
10. 速率限制
为了避免对目标网站造成过大压力,可以在请求之间设置延时。
import time time.sleep(1) # 延时1秒
相关问答FAQs
Q1: 爬虫是否合法?
A1: 爬虫本身是合法的技术,但使用爬虫抓取数据时必须遵守相关法律法规和网站的使用条款,未经允许抓取他人数据可能侵犯版权或其他权利。
Q2: 如何提高爬虫的效率?
A2: 提高爬虫效率的方法包括:并行爬取多个页面、使用多线程或多进程、优化解析逻辑、合理设置延时以避免对服务器造成过大压力等,确保代码高效且无冗余操作。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/761010.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复