


在数字化时代,数据成为了一种宝贵的资源,网站通过爬虫程序自动获取其他网站的数据,用于搜索引擎索引、市场分析、竞争情报等多种用途,这种数据抓取行为有时会对被爬网站造成沉重的服务器负担,侵犯版权,甚至泄露用户隐私,因此许多网站管理者采取各种措施来防御恶意爬虫攻击,本文将详细解析如何配置网站的反爬虫防护规则以抵御这些不受欢迎的网络爬虫。
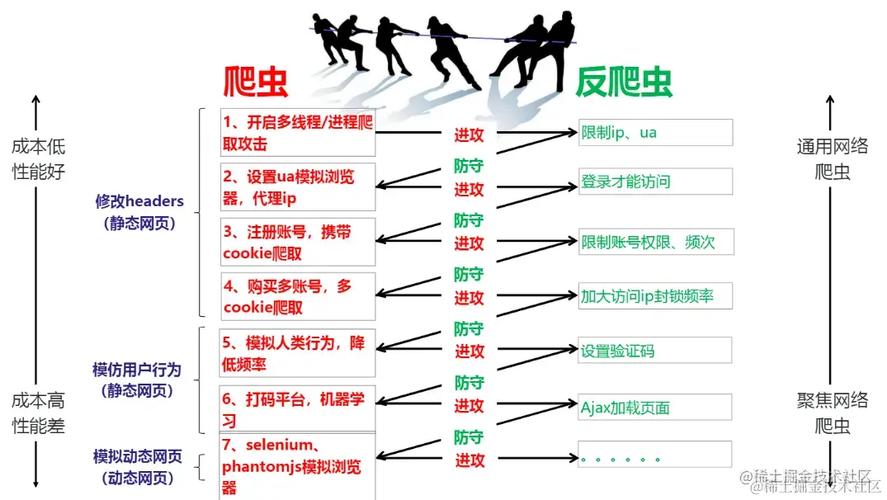

需要对爬虫的工作方式有一个基本了解,爬虫通常通过模拟合法用户的行为,发送请求到web服务器并接收响应数据,基于这一点,网站管理员可以通过多种技术手段来识别和阻止非正常的自动化访问行为。
反爬虫策略概览
反爬虫策略可以分为几个层次:
基础规则: 例如设置robots.txt文件,告诉遵循规则的爬虫哪些页面可以访问,哪些不可以。
中级规则: 包括用户行为分析,如短时间内多次访问等不符合正常人类行为的特征。
高级规则: 如动态页面呈现,必须通过JavaScript交互才能获取数据。
复合规则: 结合多种手段,比如行为分析加上JavaScript挑战。
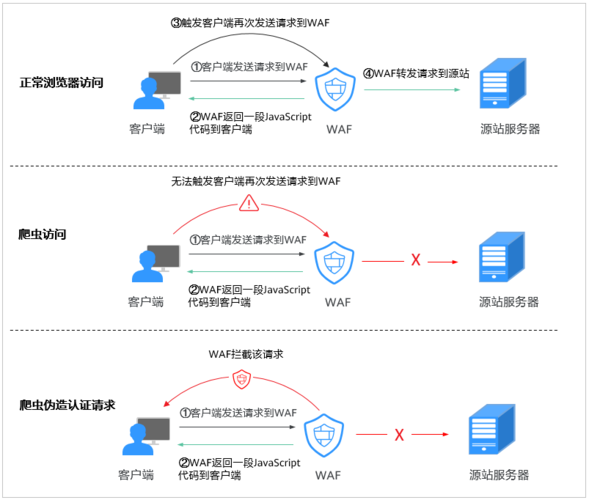
配置反爬虫防护规则
接下来是一些具体的防护手段:
1、自定义JS脚本: 由于爬虫通常无法执行或理解复杂的JavaScript代码,可以在页面中嵌入特定的JS脚本来检测是否是爬虫访问。
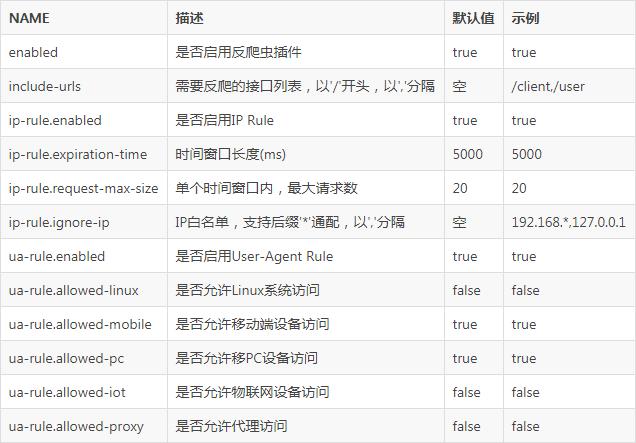
2、访问频率控制: 限制来自同一IP地址的访问频率,超出阈值则暂时封禁该IP。
3、行为分析: 分析访问者的浏览行为,如鼠标移动、点击等,异常行为可能暗示着自动化爬虫。
4、验证码: 对于一些敏感操作或频繁访问,弹出验证码要求用户证明其非自动化程序。
5、Web应用防火墙(WAF): 使用专业的安全工具,如WAF,来自动识别并阻止恶意流量。
6、API网关: 对外提供API接口取代直接爬取,有效管理数据访问权限。
7、内容混淆: 更改网页内容的呈现方式,使自动化抓取变得更加困难。
8、法律与政策: 明确告知用户和爬虫开发者你的网站数据使用政策,必要时采取法律行动保护版权。
9、用户代理检测: 检查访问者的用户代理字符串,屏蔽来自非浏览器或已知爬虫的访问。
10、Cookies测试: 验证访问者浏览器是否启用了Cookies以及是否正常支持会话。
防御爬虫攻击的重要性
保护服务器资源: 避免爬虫消耗过多带宽和服务器资源,保证服务稳定。
维护数据主权: 防止数据被无授权抓取和使用,维护企业的数据主权。
用户隐私保护: 减少通过爬虫可能泄露的用户隐私信息。
相关问答FAQs
爬虫和反爬虫之间的较量是否会一直持续?
答: 是的,随着技术的发展,爬虫技术会越来越高级,同样反爬虫技术也会不断进步,两者之间的较量预计将长期存在。
有哪些法律法规可以帮助网站防止被爬取?
答: 例如美国的《计算机欺诈和滥用法案》(CFAA)和欧盟的《通用数据保护条例》(GDPR)等,都提供了一定的法律依据来保护网站数据不被非法抓取和使用。
通过上述多个层面的防护措施,网站管理员可以有效地提高爬虫的攻击成本,降低被恶意抓取的风险,值得注意的是,在进行反爬虫配置时,也要兼顾真实用户的体验,确保不会对他们的正常访问造成影响,保持对新兴爬虫技术的警觉,及时更新防护措施,才能在爬虫与反爬虫的持久战中保持优势。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/759410.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复