


Kafka Java API是Apache Kafka提供的一个Java客户端库,用于与Kafka集群进行交互,它允许开发者在Java应用程序中生产和消费消息,以及管理和监控Kafka集群,以下是关于Kafka Java API的一些主要组件和功能的详细介绍:

1、生产者(Producer)
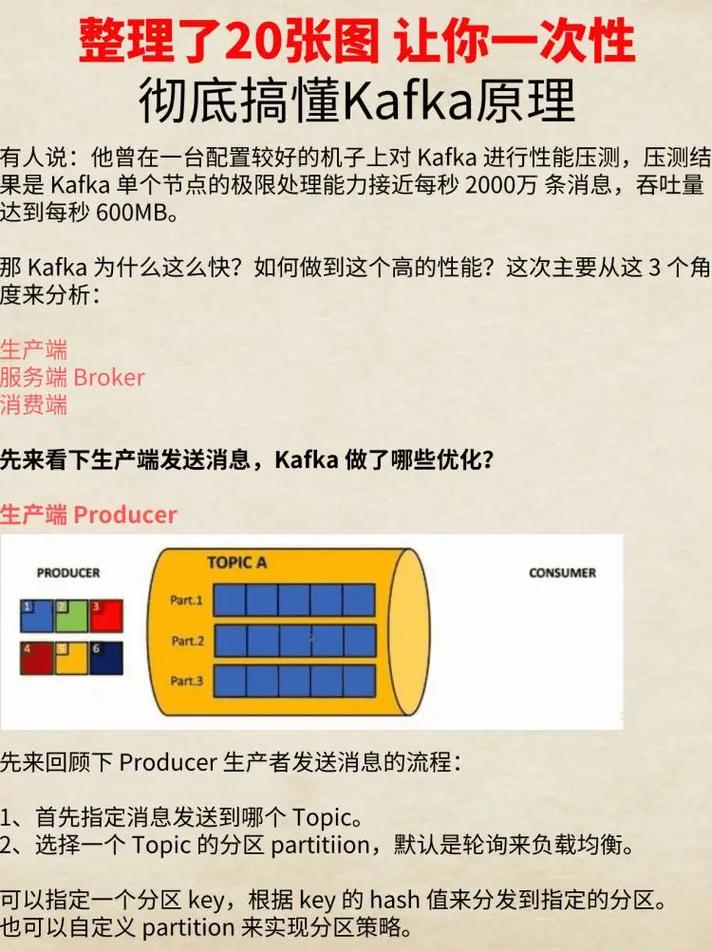
创建消息并发送到Kafka主题(Topic)。
支持同步发送和异步发送。
可以设置消息的键(Key)和值(Value),以便进行分区和排序。
支持自定义序列化器,将对象转换为字节流。
2、消费者(Consumer)
从Kafka主题(Topic)中读取消息。
支持自动提交偏移量(offset)或手动提交偏移量。
支持多种消费模式,如单线程消费、多线程消费等。
支持自定义反序列化器,将字节流转换为对象。
3、消费者组(Consumer Group)
一组消费者共享一个标识符,共同消费一个或多个主题(Topic)的消息。
每个消费者组内的消费者可以独立消费消息,互不干扰。
支持动态添加或删除消费者成员。
4、主题(Topic)
Kafka中的消息分类,类似于数据库中的表。
支持分区(Partition),提高并发处理能力。
支持副本(Replica),提高数据的可靠性和容错性。
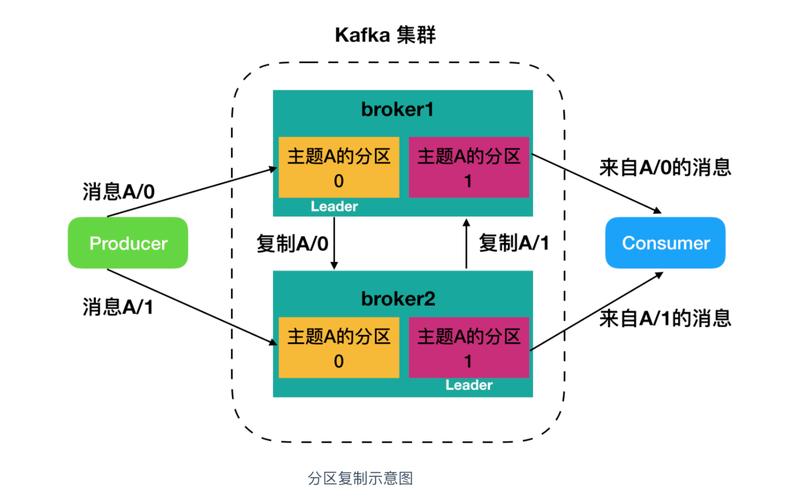
5、分区(Partition)
主题(Topic)的物理分组,每个分区包含一部分消息。
分区可以提高并发处理能力,因为消费者可以并行消费不同分区的消息。
分区还可以实现负载均衡,避免单个分区成为性能瓶颈。
6、副本(Replica)
分区的备份,用于提高数据的可靠性和容错性。
副本分布在不同的Kafka节点上,当某个节点故障时,其他节点上的副本可以继续提供服务。
副本之间通过ISR(InSync Replicas)机制保持同步,确保数据的一致性。
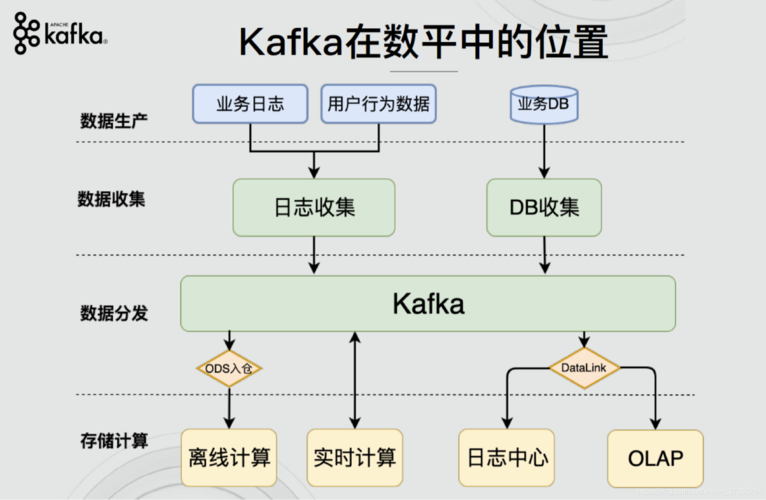
7、Kafka集群(Cluster)
由多个Kafka节点组成的分布式系统。
节点之间通过Zookeeper进行协调和管理。
支持水平扩展,可以通过增加节点来提高系统的吞吐量和容错能力。
8、Kafka Streams
Kafka提供的流处理框架,用于构建实时数据流应用。
支持状态存储和窗口操作,可以实现复杂的数据处理逻辑。
可以与其他Kafka组件(如生产者、消费者)无缝集成。
9、Kafka Connect
Kafka提供的连接器框架,用于将外部系统的数据导入或导出到Kafka。
支持多种源和目标连接器,如JDBC、Elasticsearch等。
可以将Kafka作为数据管道的中心,实现数据的实时传输和处理。
10、Kafka Tools
Kafka自带的命令行工具,用于管理和监控Kafka集群。
如kafkatopics.sh用于创建、删除和列出主题;kafkaconsoleconsumer.sh用于消费消息等。
还提供了RESTful API供开发者使用。
这些组件和功能使得Kafka Java API成为一个功能强大、易于使用的分布式消息系统,广泛应用于实时数据处理、日志收集、事件驱动架构等领域。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/757453.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复