

Kafka分布式消息服务_分布式消息服务Kafka版
Kafka是一款高吞吐、可持久化、可水平扩展的分布式消息流处理中间件,支持流式数据处理等多种特性,采用分布式消息发布与订阅机制,在当今的数字化时代,随着数据量的飞速增长和实时处理需求日益突出,分布式消息服务如Kafka已经成为构建高性能、可扩展的数据处理系统的关键组件,Kafka以其独特的设计理念和强大的功能特性,在日志收集、流式数据传输、在线/离线系统分析、实时监控等领域得到了广泛的应用,以下将详细介绍Kafka的核心概念、特性以及在分布式架构中的应用。
核心概念
1.消息:Kafka 中的数据单元被称为“消息”,每条消息都包含键、值和时间戳。
2.主题:消息的类别称为“主题”(Topic),生产者发送消息到特定的主题,消费者从特定的主题接收消息。
3.生产者:发送消息到 Kafka 集群的设备或应用程序称为“生产者”(Producer)。
4.消费者:从 Kafka 集群消费消息的设备或应用程序称为“消费者”(Consumer)。
5.经纪人:Kafka 集群由一个或多个服务器组成,每个服务器称为“经纪人”(Broker)。
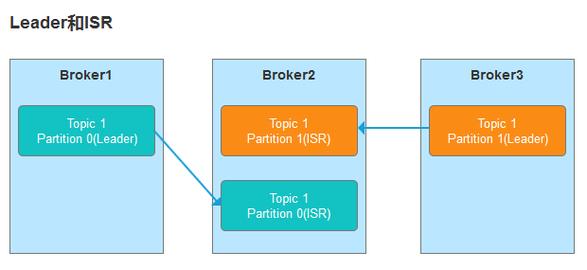
6.分区:主题可以被分为多个分区,以实现数据的并行处理和负载均衡。
7.副本:为了保证数据的高可用性,每个分区可以有一个或多个副本分布在不同的经纪人上。
特性与优势
1.高吞吐量:Kafka 能够处理每秒数百万条消息的写入和读取,满足大数据场景下的需求。
2.持久化存储:Kafka 可以将消息持久化存储在硬盘上,防止数据丢失。
3.可扩展性:通过增加经纪人数量,Kafka 可以轻松水平扩展以处理更多的消息。
4.分布式:Kafka 的分布式设计允许系统在多个服务器上运行,提高了系统的容错能力和伸缩性。
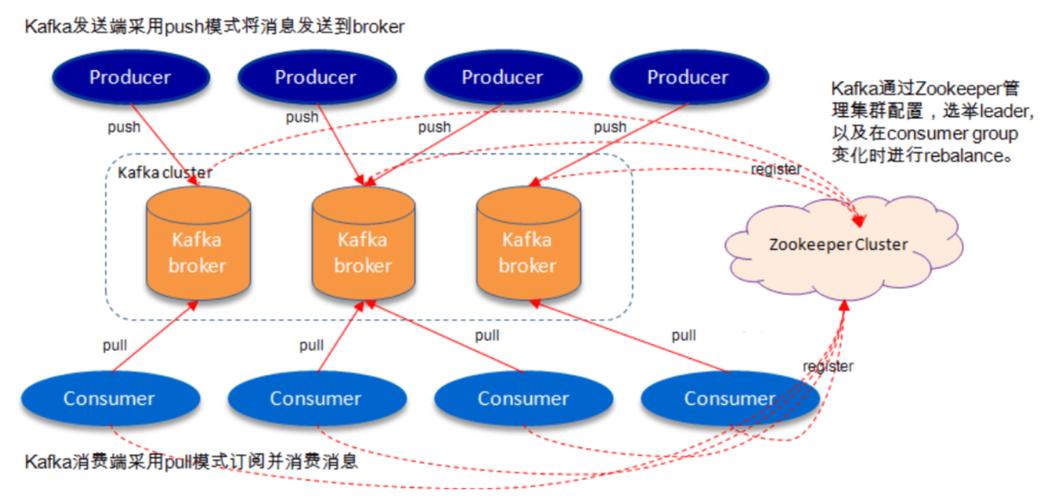
5.数据备份:通过副本机制,Kafka 提供了数据冗余,确保了数据的可靠性。
应用场景
1.日志收集:Kafka 常用于收集来自分布式系统的日志数据,便于集中处理和分析。
2.实时数据处理:Kafka 支持实时流式数据处理,适用于需要快速响应的场景。
3.数据集成:Kafka 可以作为不同数据源和数据消费平台之间的数据集成枢纽。
4.事件驱动架构:Kafka 的消息传递机制非常适合构建事件驱动的微服务架构。
5.大数据处理:Kafka 可以与 Hadoop、Spark 等大数据处理框架结合使用,进行批量和实时数据处理。
Kafka作为一个高性能、可扩展的分布式消息服务,其设计哲学和技术实现为现代数据处理带来了革命性的变化,通过深入理解Kafka的核心概念、特性以及在分布式架构中的应用,开发人员和架构师可以更好地利用这一工具来构建可靠、高效、可扩展的数据处理系统。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/756562.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复