

1、UserAgent管理
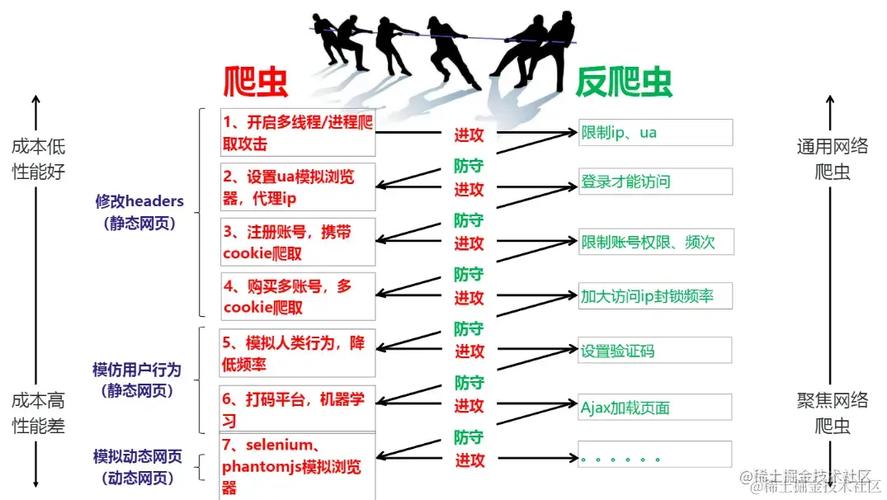

在爬虫开发过程中,使用单一的UserAgent可能会引起网站的警觉,为避免此问题,开发者可以构建一个UserAgent池,包含多个浏览器的UA信息,并在发送请求时随机选择其中之一,这样可以减少被网站识别为爬虫的风险。
使用fakeuseragent模块可以方便地生成随机的UserAgent,安装该模块后,开发者可以在请求中引入不同的UserAgent,从而模拟不同的浏览器环境,这种方法不仅可以提高爬虫的隐蔽性,还能增加其适应不同网站的能力。
2、缓存策略配置
合理配置缓存策略对于提升爬虫效率至关重要,Scrapy框架允许开发者通过设置中间件来实现缓存管理,在settings.py文件中可以调整缓存相关参数,如缓存大小、存储方式等,以优化爬虫性能和资源消耗。
缓存机制可以帮助爬虫减少对同一资源的重复请求,降低服务器负载,并加快数据获取速度,特别是在爬取大量数据或高频访问时,缓存策略的配置显得尤为重要。
3、反爬虫防护规则配置
网站管理员可以通过配置反爬虫防护规则来防御恶意爬虫攻击,这包括设置特定的JS脚本,以识别并阻止自动化工具的请求,可以设定规则防护除特定路径外的所有请求,或者仅允许某些特定的UserAgent访问。
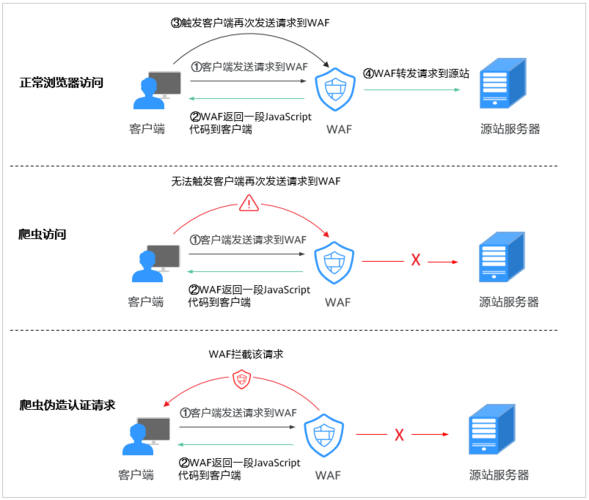
进一步的措施可能包括识别访问者的IP地址和请求频率,若发现异常频繁的请求,则自动屏蔽该IP,结合WAF(Web Application Firewall)功能,可以从多个层面增强网站的安全保护。
4、动态页面处理技术
对于采用JavaScript动态加载内容的网站,传统爬虫可能无法有效抓取数据,利用如Puppeteer或Pyppeteer这样的工具,可以在爬虫中模拟真实浏览器行为,执行JavaScript代码并获取动态生成的内容。
这种技术支持爬虫开发者处理更复杂的前端技术,如AJAX和DOM操作,实现更精准的数据抓取,尤其是面对需要用户交互才能显示内容的网站,这类技术提供了有效的解决方案。
5、爬虫策略法律与伦理考量
开发和使用爬虫时必须考虑合法性及伦理道德,遵守相关法律法规,尊重目标网站的Robots.txt文件,避免侵犯版权或造成服务拒绝攻击。
合理的爬虫设计应当减少对目标网站的影响,避免在高峰时段进行大规模抓取,确保数据采集的行为不会对网站正常运营造成负面影响。
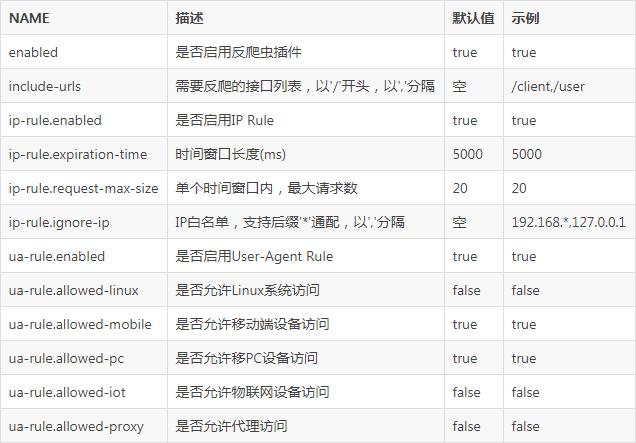
通过这些策略和技术的应用,爬虫开发者不仅能提高爬虫的效率和安全性,还能有效遵守网络道德规范,维护互联网生态平衡。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/756240.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复