

在面对海量数据存储与管理时,选择一种大容量数据存储方案和数据库系统显得尤为重要,本文将深入探讨几种主流的大容量数据存储解决方案及数据库系统,分析其适用场景及优势,并提供实务中的应用示例,帮助理解如何根据具体需求选择合适的存储系统。
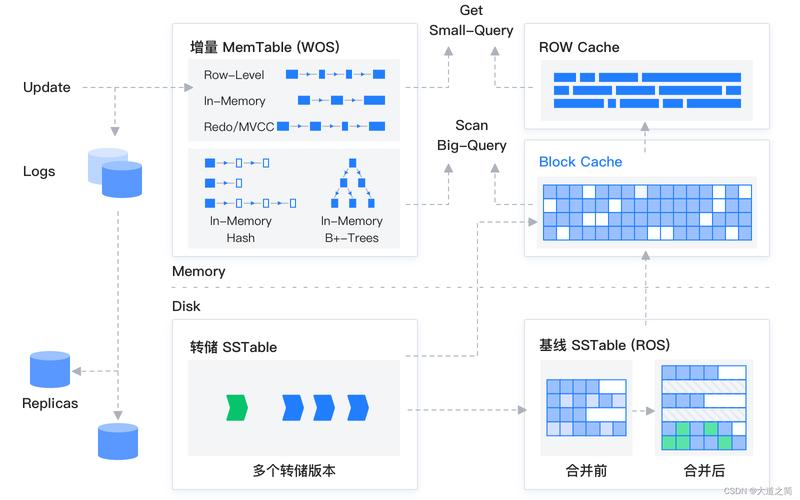
大容量数据存储方案
1、分布式计算系统
Hadoop:适用于处理复杂的大数据工作负载,特别是在不需要即时响应的离线场景中,其主要优点是能够存储和处理PB级别的数据。
Spark:相比Hadoop,Spark提供了更快的数据处理能力,尤其适合于需要快速迭代的数据分析任务。
Storm:当涉及到需要实时处理的数据流时,Storm提供了高效的解决方案,常用于在线的实时的大数据处理,如实时监控和实时分析等场景。
2、数据备份策略
321原则:一种常用的数据备份策略,包括3份备份、2种介质、1份异地备份,以确保数据的安全性和可靠性。
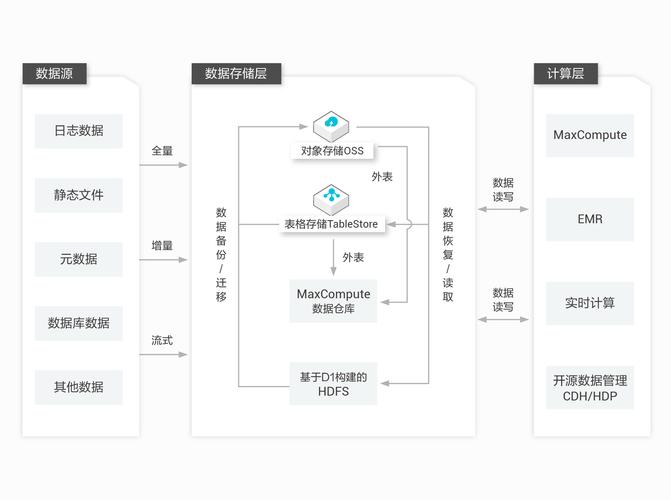
3、分布式与集群设计原则
集群技术:通过多台服务器实现同一业务,旨在提升系统的并发处理能力和容错能力。
分布式系统:将不同业务分布在不同服务器中,以优化单个模块性能和整体系统的扩展性。
4、数据抽取与集成
对于多样化的数据来源,如企业内部数据库、互联网数据和物联网数据,需要进行有效的数据抽取与集成,以保证数据的完整性和一致性。
大容量数据库系统
1、NoSQL数据库
MongoDB:腾讯云的MongoDB服务提供了一个高性能、弹性可扩展且自动容灾的文档型数据库解决方案,支持跨文档事务,适用于高速成长的数据量需求。
2、分布式关系数据库
PolarDBX:阿里云的PolarDBX为一个高性能的云原生分布式数据库,提供高吞吐和大存储空间,同时具备低延时和高可用性特点。
3、传统关系型数据库
MySQL:虽然早期的MySQL有表大小限制,但后续版本通过使用InnoDB存储引擎等方式突破了这一限制,使得MySQL可以处理更大的数据集,其容量上限主要由操作系统对文件大小的限制决定。
4、云数据库服务
RDS MySQL:基于阿里巴巴MySQL源码分支开发的RDS MySQL版,经过大规模并发和大数据量的考验,提供了包括备份恢复、读写分离等多项高级功能。
相关问答FAQs
Q1: 如何选择适合的大容量数据存储方案?
A1: 选择数据存储方案时应考虑数据的类型(结构化或非结构化)、访问频率、实时性需求以及预算等因素,如果数据量大且多为非结构化数据,可以考虑使用Hadoop或Spark这类分布式系统;而需要高并发和实时处理的场景则可能更适合Storm。
Q2: 如何确保数据的安全性和持久性?
A2: 实施多重备份策略,如321原则,可以有效提高数据的可靠性,利用云服务商提供的自动备份、容灾和多地冗余存储功能也是确保数据安全的重要措施。
选择合适的大容量数据存储方案和数据库系统是确保数据可靠性和高效访问的关键,无论是分布式计算系统、备份策略、还是具体的数据库类型选择,都需要根据实际的业务需求、数据特性及预算进行细致考量。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/753933.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。