


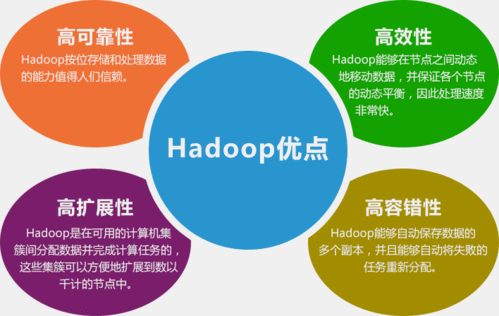
Hadoop是一个开源的分布式计算和存储框架,由Apache基金会开发和维护,主要用于提高大数据的计算能力和解决大数据的存储问题,Hadoop的作用是在计算机集群环境中营造一个统一而稳定的存储和计算环境,并能为其他分布式应用服务提供数据平台支撑,具体分析如下:

1、基础架构:
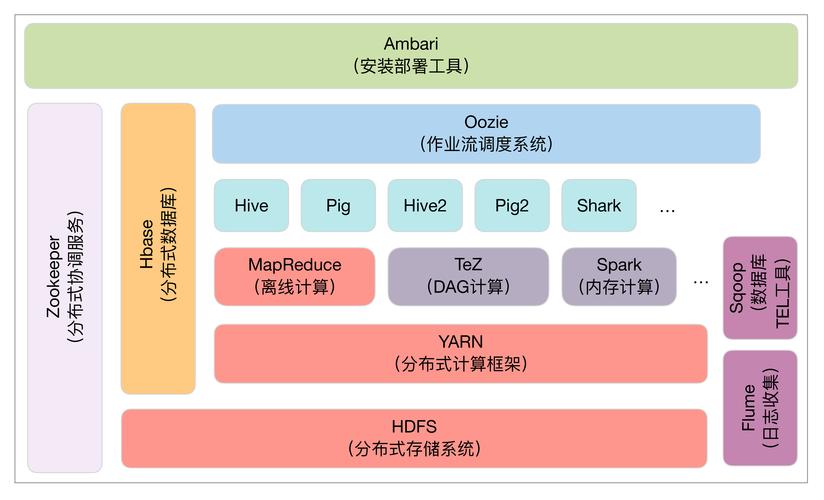
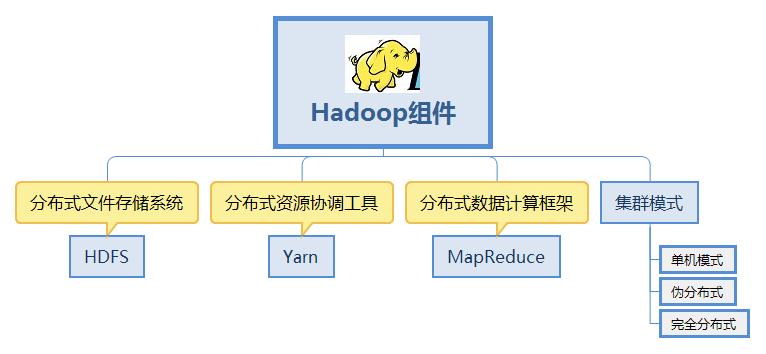
Hadoop的基础架构包括两个主要组件:HDFS(Hadoop Distributed File System)和MapReduce,HDFS是Hadoop的分布式文件系统,负责在集群中存储和管理数据,MapReduce则是一个编程模型,用于处理和生成大数据集。
HDFS采用主从架构,由一个NameNode(命名节点)和多个DataNode(数据节点)组成,NameNode负责管理文件系统的元数据,而DataNode则存储实际的数据块。
MapReduce将计算过程分为映射(Map)和归约(Reduce)两个阶段,Map阶段对数据进行分割和处理,Reduce阶段则将结果汇总输出。
2、数据处理:
Hadoop的设计使其能够在多个硬件节点上分发和处理数据,从而在不增加单个节点负载的情况下,提高数据处理的效率和速度,这种分布式计算方式特别适用于需要处理PB级别(Petabyte,千万亿字节)海量数据的应用场景。
Hadoop可以在廉价硬件上部署,降低了成本,通过数据冗余存储,提高了系统的容错能力。
3、职业角色:
随着Hadoop的应用越来越广泛,围绕Hadoop产生了多种职业角色,如Hadoop开发人员、Hadoop管理员、Hadoop架构师、Hadoop测试人员和大数据分析师等。
Hadoop开发人员负责编写基于Hadoop的程序,管理和查看日志文件,并通过各种工具进行集群协调和服务管理。
Hadoop管理员则负责维护HDFS,管理Hadoop集群,并跟踪连接性和安全性问题。
Hadoop架构师设计系统的工作方式,并管理Hadoop解决方案的整个生命周期。
4、行业应用:
Hadoop广泛应用于日志处理、ETL(Extract, Transform, Load)、机器学习、搜索引擎和数据挖掘等领域,使用Flume、Logstash、Kafka和Spark Streaming进行实时日志处理分析,以及在推荐系统中进行个性化广告推荐。
许多大型IT公司,如EMC、Microsoft、Intel、Teradata和Cisco,都增加了在Hadoop方面的投入,使其成为大数据处理的标准基础设施。
Hadoop的出现和发展极大地推动了大数据技术的进步,使其在存储和计算海量数据方面表现出色,对于有志于从事大数据相关工作的人员来说,学习Hadoop不仅能够提升自身技能,还能为未来的职业发展提供更多机会和前景。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/747022.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复