

HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,旨在处理大量的数据,以下是对hbase的特点的具体分析:
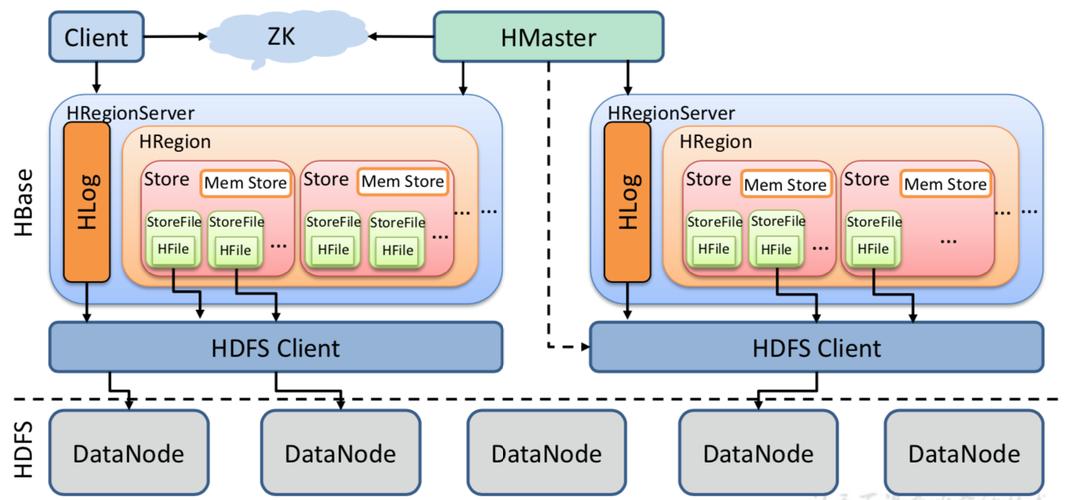

1、数据模型和存储机制
面向列的存储方式:与关系型数据库的基于行模式存储不同,HBase采用基于列的存储方式,每个列族都由几个文件保存,不同列族的文件是分离的。
数据版本管理:执行更新操作时,HBase不会删除旧数据版本,而是生成一个新的版本,使得数据的旧有版本仍然得以保留。
2、可伸缩性与扩展性
灵活的水平扩展:HBase能够轻易地通过在集群中增加或减少硬件数量来实现性能的伸缩。
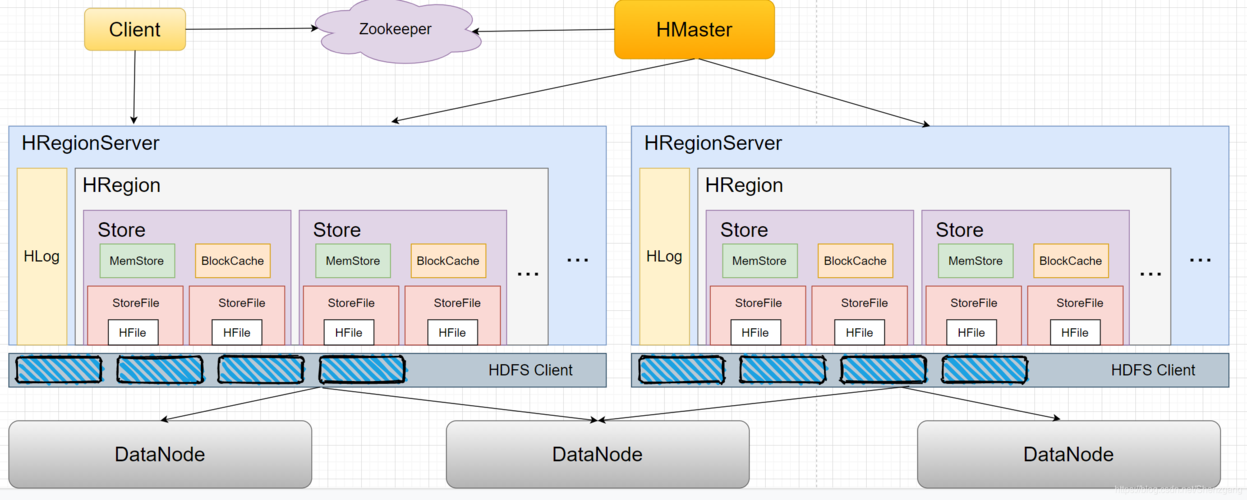
海量存储能力:设计用于处理非常庞大的表,支持通过水平扩展的方式处理由超过十亿行数据和数百万列元素所组成的数据表。
3、高并发读写支持
支持高并发操作:可以提供高并发的读写操作,并利用廉价的计算机来处理大规模数据。
实时查询优化:默认对RowKey做了索引优化,即使数据量庞大,根据RowKey查询的效率也会很高。
4、可靠性与容错性
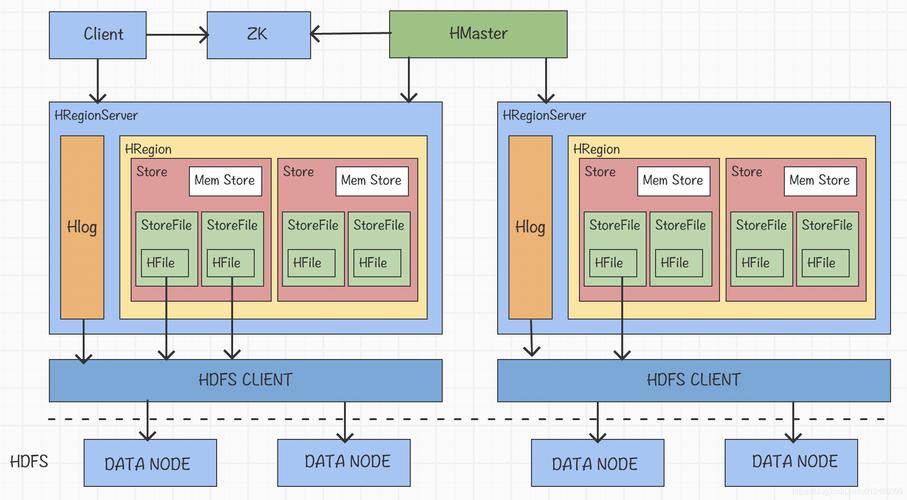
WAL机制:保证了数据写入时不会因集群异常而导致写入数据丢失。
Replication机制:确保在集群出现严重问题时,数据不会发生丢失或损坏。
5、简易性与灵活性
简单的数据模型:将数据存储为未经解释的字符串,避免了复杂的表与表之间的关系。
动态增加列:数据表内的列可以做到动态增加,并且列为空的时候不存储数据,从而节省存储空间。
6、多语言API支持
丰富的API支持:支持Java、Thrift和REST等语言的API来进行数据存取编程。
7、自动分片与并行处理
自动分片:表中的数据通过Region分布在集群上,并会随着数据的增长自动拆分和重新分布。
MapReduce支持:可以利用MapReduce进行大规模并行处理。
结合上述七个特点,HBase作为一个分布式列式数据库,其设计主要针对的是处理大规模数据集的场景,它不仅提供了高效的数据读写能力,还具有优秀的横向扩展性和高可靠性,尽管在某些特定的应用场景(如需要复杂查询和事务支持的环境)中可能不是最佳选择,但在需要处理海量数据、进行高效随机读写和实时查询的场合下,HBase显示出了其强大的优势。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/746954.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复