


在当今数字化时代,网站开发不仅仅是关于创建在线平台,而是更深入地涉及到如何通过特定的功能实现与用户的有效互动,获取目标库分组中的目标数量是一项关键的技术功能,这对于很多以数据为中心的网站尤其重要,下面将详细探讨如何开发一个能获取目标库分组中的目标数量的网站功能:
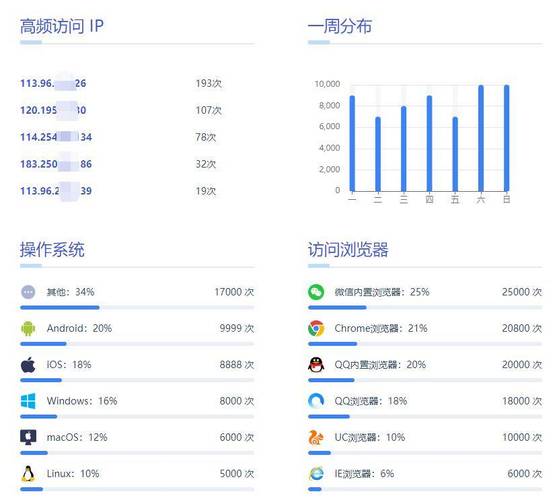

功能简介
功能定义:允许用户通过接口查询目标库分组中的目标数量。
适用设备:好望协议设备,确保设备安装了目标算法。
设备要求:NVR800需切换到人卡模式,SDC直连需要开启目标库对比。
API接口:URI GET /v1/{user_id}/targets/count,这是获取目标数量的接口地址。
技术路线
需求分析:确定网站的目标用户及其需求,如监控人员可能需要实时了解特定区域的目标数量。
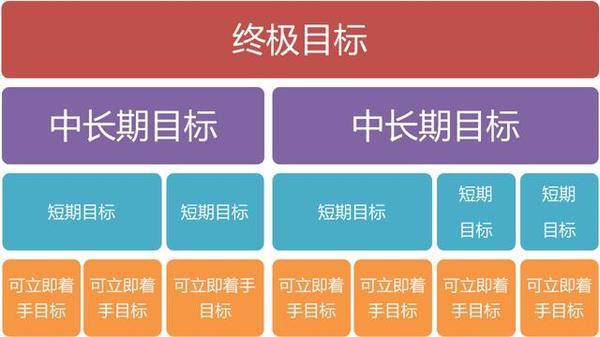
设计规划:设计用户友好的界面来展示目标数量,以及设置权限,确保只有授权用户才能访问敏感数据。
开发步骤:从数据库设计到后端逻辑实现,再到前端页面展示,每一步都需要细致的设计与实现。
测试验证:进行严格的测试,包括单元测试、集成测试和性能测试,确保功能的准确性和稳定性。
关键组件
数据库设计:设计一个能够高效存储和检索目标数据的数据库是基础。
后端逻辑:后端需要处理来自前端的请求,执行数据库查询操作,并返回正确的目标数量。
API接口:提供稳定的API供前端调用,是前后端交互的桥梁。
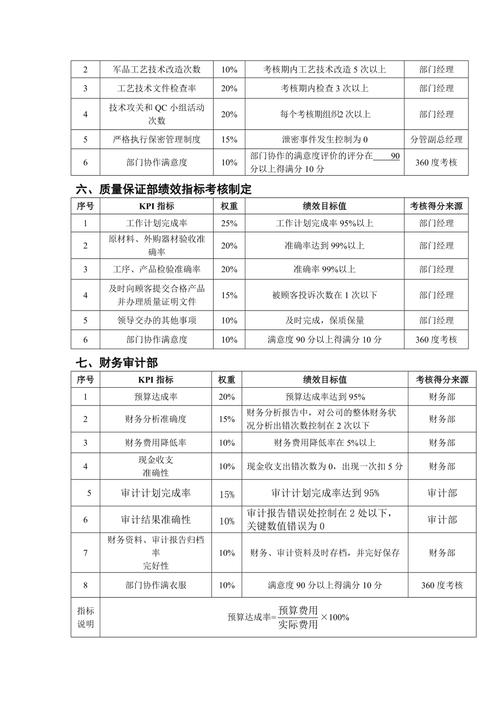
前端展示:前端不仅要展示数据,还要进行适当的数据格式化,提高用户的阅读体验。
实现策略
抓包工具:使用抓包工具获取目标网站的JavaScript代码,了解其数据加载方式。
爬虫框架:利用爬虫框架自动化获取目标网站的数据,为数据分析提供原始材料。
页面结构分析:深入分析目标网站的页面结构,确定爬取目标和策略。
URL规律研究:研究目标网站URL的构成规律,便于后续的自动化数据抓取。
难点与解决
数据安全:在传输过程中加密数据,防止数据被截获。
数据实时性:采用WebSocket等技术实现前后端的实时通信,确保数据的实时更新。
用户体验:优化前端设计,减少用户等待时间,提供更加流畅的用户体验。
兼容性问题:确保功能在不同的设备和浏览器上都能正常工作,特别是在好望协议设备上的表现。
未来展望
技术迭代:随着技术的发展,不断优化和升级功能实现的方式,提高系统的整体性能和可用性。
数据分析深度:利用机器学习等技术对获取的数据进行更深入的分析,挖掘更多有价值的信息。
用户反馈机制:建立有效的用户反馈机制,根据用户的使用情况和建议不断调整和优化产品。
法规遵守:随着数据保护法规的日益严格,确保所有数据的处理都符合相关法律法规的要求。
获取目标库分组中的目标数量是一个重要的网站功能,它不仅需要技术上的精细实现,还需要在法律和伦理方面谨慎行事,通过上述的详细介绍,我们可以对此功能的开发有一个全面而深入的理解,随着技术的不断进步和用户需求的不断变化,这一功能的实现也将不断演进,以满足更高的标准和更广泛的应用场景。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/746331.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复