


K近邻算法(KNN)是一种基于实例的学习,在机器学习和数据挖掘中有着广泛的应用,这种算法因其简单、直观的特点而受到青睐,但也存在计算量大、内存消耗高等缺点,近年来,研究者对KNN算法进行了多种改进,其中一种重要的改进是引入深度学习技术,形成了所谓的“K跳算法”,以下是对这一改进的详细解析:

深度学习与KNN的结合
1. 深度学习优化特征表示
深度学习通过多层神经网络能够学习到数据的深层特征,这些特征比原始数据更具表现力,将深度学习得到的特征用于KNN算法,可以提升算法的准确性,深度学习模型如自编码器、卷积神经网络(CNN)等可以被用来预训练数据,提取出更有利于分类或回归任务的特征。
2. K跳算法的原理
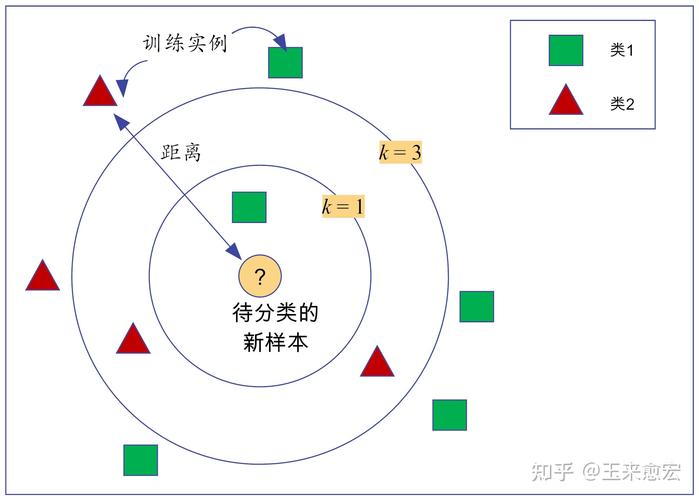
基本概念:传统的KNN算法直接计算待分类样本与已知标签样本之间的距离,而K跳算法则在此基础上增加了“跳数”的概念,所谓“跳”,指的是在特征空间中,通过深度学习模型建立起的样本间的关系。
算法步骤
1. 使用深度学习模型预处理所有样本,得到每个样本的深层特征表示。
2. 定义“跳数”:一跳可以定义为与当前样本在特征空间中最相邻的样本,二跳则为这些一跳邻居的一跳邻居,以此类推。
3. 根据问题的具体需求,选择适当的跳数,计算在这些“跳”内的所有样本。
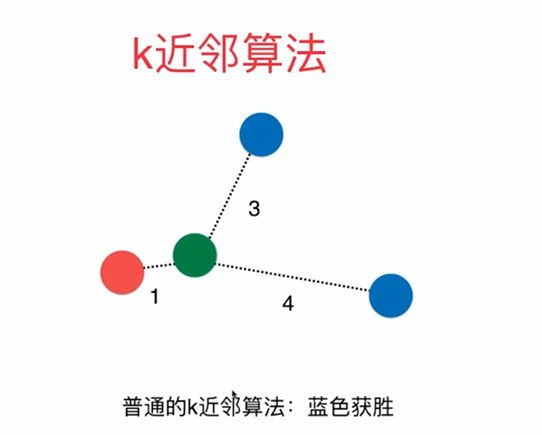
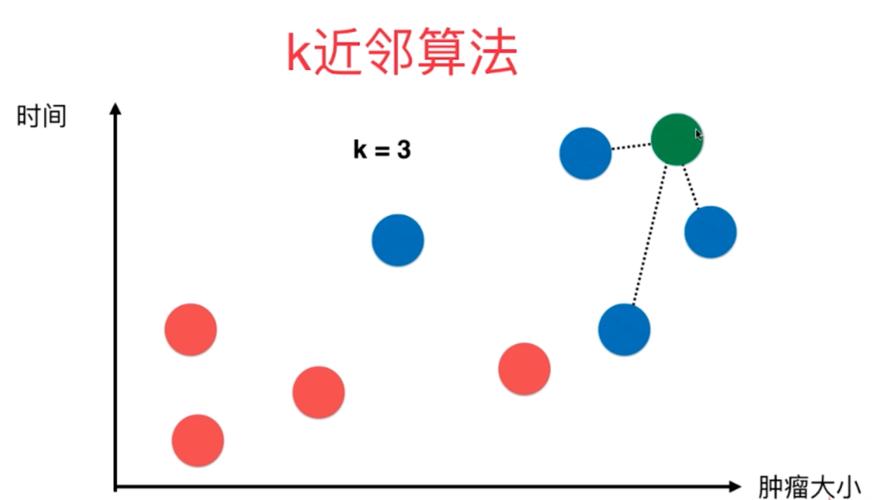
4. 应用传统KNN的投票或平均策略,得出最终的分类或回归结果。
3. 算法优势
减少计算量:通过限制跳数,可以在不牺牲太多准确性的前提下,显著减少计算距离的次数,从而减轻计算负担。
增强鲁棒性:多跳的引入使得算法能够考虑到样本间的间接关系,增强了对噪声和异常值的鲁棒性。
利用深层特征:深度学习所得到的高级特征能够更好地捕捉数据的内在规律,提高分类或回归的准确性。
应用场景分析
K跳算法由于其改进的特性,特别适合于以下场景:
1、图像处理:在图像识别、目标检测等任务中,深度学习能够提取丰富的视觉特征,K跳算法进一步提升分类精度。
2、推荐系统:在用户商品交互数据上应用K跳算法,可以发现用户间的间接关联,提供更为精准的推荐。
3、生物信息学:基因表达数据分析中,K跳算法能够帮助识别功能相似的基因,促进生物标记物的发现。
性能评估与参数调优
在实际应用中,为了最大化K跳算法的性能,需要进行参数调优:
1、跳数的选择:跳数过多可能导致计算复杂度上升,过少则可能丢失有用信息,一般通过交叉验证来确定最佳跳数。
2、距离度量方式:虽然深度学习提供了丰富的特征表示,但选择合适的距离度量方式(如欧氏距离、余弦相似度等)仍然重要。
3、深度学习模型的选择:不同的模型(如CNN、RNN、Transformer等)适用于不同的数据类型和任务,需要根据具体情况来选择。
上文归纳与展望
K跳算法作为KNN算法的一种改进,通过结合深度学习技术和引入跳数概念,有效提升了算法的性能,尽管存在参数调优等挑战,但其在多个领域的应用潜力值得进一步探索,随着深度学习技术的不断进步和计算资源的增加,K跳算法有望在更多高维数据和复杂任务中展现其优越性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/745894.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复