


使用Kettle导入大量数据库的方法

Kettle 是一款强大的开源ETL(Extract, Transform, Load)工具,也广为人知的别名是Pentaho Data Integration,它主要用于数据抽取、转换和加载等操作,下面将详细介绍如何使用Kettle进行数据的导入操作:
1、环境配置
系统变量配置:为保证Kettle正常运行,需正确设置JAVA_HOME环境变量,变量值设置为JDK的安装目录。
资源库连接:在Kettle中选择连接开发方案,选定资源库方式后录入相应的数据库信息,包括主机名称、数据库名、端口号以及登录账号和密码。
2、数据库连接配置
文件夹建立与管理:在资源库中建立文件夹,对数据库连接进行配置,以便后续开发使用。
数据源/数据仓库配置:配置好数据库连接后,即可设定数据抽取的源以及数据加载的目标。
3、转换和作业创建
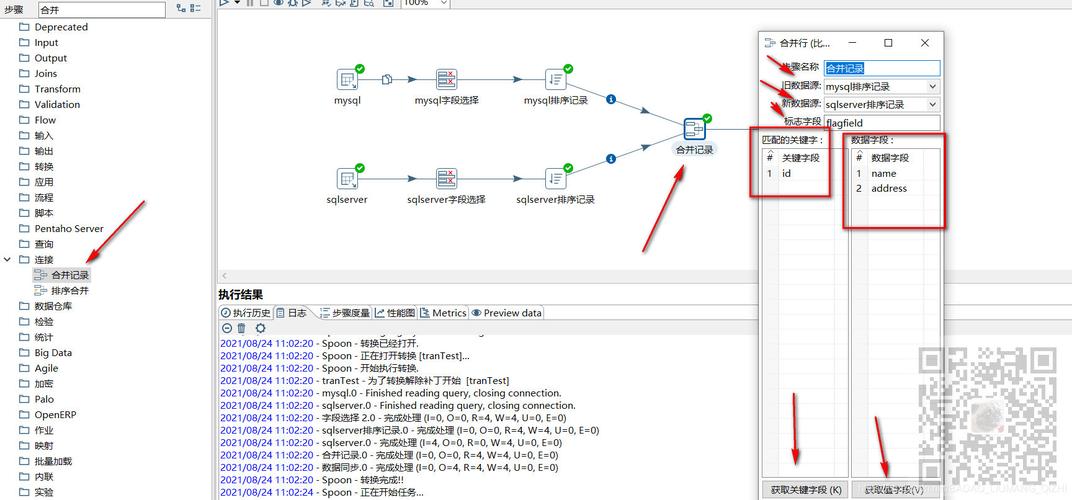
新建转换(Transformation):在工具中新建转换并归属到指定文件夹,转换是数据处理的核心单元,通过不同的步骤实现数据提取、转换和加载。
转换图搭建:使用Spoon工具搭建转换图,定义从数据源到目标的数据流,通过拖拽不同的步骤完成数据流设计。
作业(Job)创建:作业定义了多个转换的调度和控制,确保ETL过程按照预定的顺序和依赖关系执行。
4、数据抽取与转换
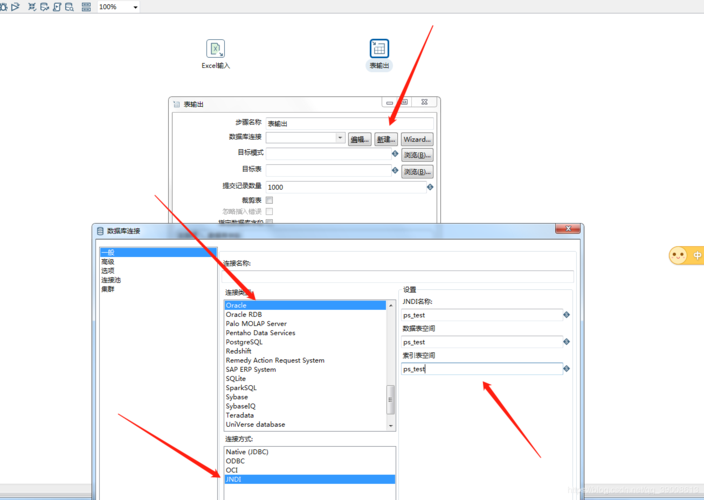
表输入:在转换中建立表输入步骤,指定数据源和要抽取的表及字段,这是数据抽取的起点。
数据清洗和转换:利用Kettle提供的各种步骤进行数据清洗和转换,如筛选、去重、数据格式转换等。
5、数据加载与执行
写入目标:在转换流程的最后,加入输出步骤,指定数据加载的目标,比如另一数据库或者文件。
本地测试与调试:使用Spoon进行本地的测试和调试,确保各个步骤按照预期工作。
生产执行:通过Pan和Kitchen在生产环境中执行转换和作业。
6、监控与管理
使用Carte进行监控:Carte提供了Web界面,可以远程监控和管理Kettle的执行情况。
7、应用场景举例
数据仓库建设:Kettle能够处理来自多个异构数据源的数据,非常适用于构建数据仓库的场景。
在深入了解Kettle的操作之后,还需注意以下几个要点:
确保JAVA_HOME环境变量配置正确,否则可能影响Kettle的启动和运行。
在进行数据抽取前,清晰定义数据源和目标的结构和类型,避免数据不一致导致的错误。
设计转换和作业时,应充分考虑错误处理和日志记录,便于问题追踪和解决。
在生产环境下,定期检查Kettle运行状况及时调整性能瓶颈,保障数据加载的效率和稳定性。
Kettle作为一款开源的ETL工具,提供了丰富的功能来支持数据抽取、转换和加载操作,通过上述步骤,可以实现高效的数据迁移和转换,不仅适用于数据仓库的建设,还可满足不同业务场景下的数据集成需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/744050.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复