


探索CarbonData
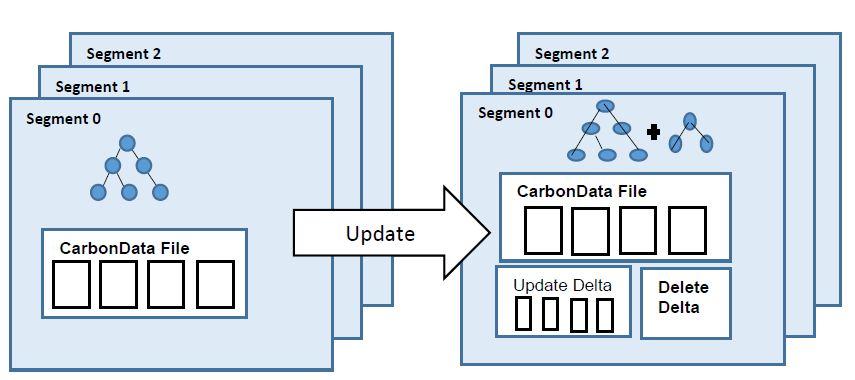

CarbonData是专为处理大规模数据分析而设计的Apache Hadoop本地文件格式,它结合了列式存储、索引、压缩和编码技术,旨在显著提升查询性能,这种格式的核心优势在于其能够针对大量数据执行快速查询,特别是在需要快速洞察和分析的场景中。
在当今数据驱动的商业环境中,能够迅速从海量数据中提取有价值信息的能力变得至关重要,传统的行式存储系统在处理大型数据集时常常面临性能瓶颈,尤其是在执行复杂的分析查询时,相比之下,CarbonData的列式存储结构显著减少了不必要的数据处理,因为只有相关的列被加载到内存中进行处理。
CarbonData不仅仅是文件格式的创新,它还整合了多种优化策略以加速查询过程,其中之一是多级索引系统,该系统允许高速访问表中的数据,无需扫描整个数据库,这种索引机制有效地减少了查询时间,尤其在进行过滤和聚合操作时更为明显,CarbonData的压缩和编码技术也极大地减少了数据的物理存储需求,同时提高了数据加载和查询的速度。
在数据编码方面,CarbonData采用了先进的编码方案,如字典编码和运行长度编码,这些方法都旨在减少存储空间并加快数据处理速度,通过使用字典编码,重复的数据值被替换为较小的代码,这既减少了存储需求,也提高了查询效率。
从应用的角度来看,CarbonData与Apache Spark的集成为用户提供了一个强大的工具,用于实时数据分析,这种集成不仅扩展了Spark的处理能力,还使得用户能够在不迁移现有数据的情况下,直接利用Spark的计算优势来分析存储在Hadoop上的数据。
尽管CarbonData带来了许多优势,但它的成功实施还需要考虑到一些关键因素,对于初次接触CarbonData的用户来说,适当的培训是必不可少的,以确保他们能够充分利用其功能,虽然CarbonData在处理大型数据集时表现出色,但较小或不太复杂的数据集可能不会显示出显著的性能提升,选择合适的用例是实现最佳性能的关键。
Apache CarbonData作为一种先进的大数据文件格式,通过其独特的列式存储及多重优化策略,显著提升了数据处理的速度和效率,无论是在数据分析的精确性还是在查询响应时间的缩短上,CarbonData都提供了一种有效的解决方案,尤其适合需要快速洞察和处理大规模数据集的场景,随着技术的不断进步和应用范围的扩大,预计CarbonData将在未来的数据分析领域扮演更加重要的角色。
相关问答FAQs
问题1:CarbonData支持哪些类型的查询优化?
答案:CarbonData特别设计了多种查询优化策略,包括多级索引、高效的压缩和编码技术等,这些优化策略旨在提高包含filter、aggregation和count distinct等分析查询的性能,帮助用户在商用集群上获得对TB至PB级别数据的快速响应。
问题2:如何将现有的Hadoop数据迁移到CarbonData?
答案:将现有Hadoop数据迁移到CarbonData通常涉及几个步骤:需要确定要迁移的数据;使用数据转换工具将数据转换为CarbonData支持的格式;将转换后的数据加载到CarbonData表中,具体操作可能需要根据实际数据结构和系统环境进行调整,建议参考官方文档或咨询经验丰富的技术人员。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/743946.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复