


数据量化是现代信息时代的重要任务,尤其是在数据驱动的决策制定过程中,本文将详细介绍如何有效处理大量数据,并对其进行量化分析。
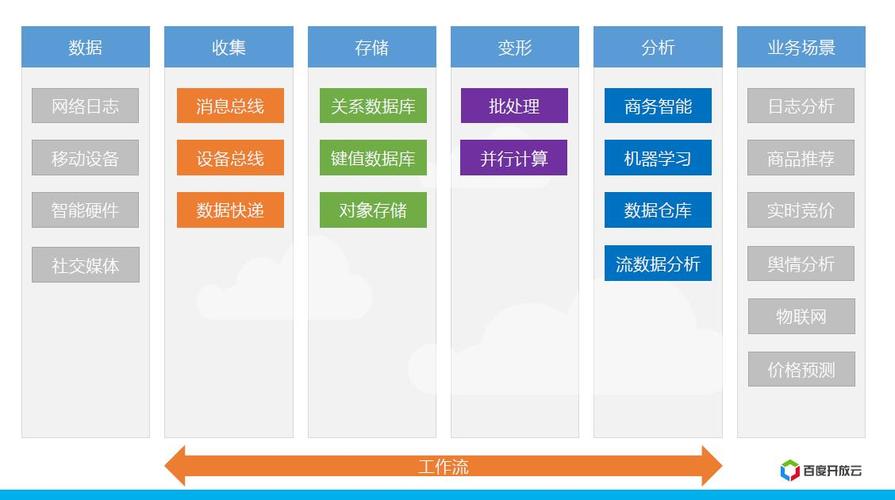

数据收集与预处理
数据收集
处理大数据量的第一步是数据的收集,这通常涉及从多个来源获取数据,包括社交媒体、在线交易记录、传感器设备等,在这个阶段,重要的是确保所收集的数据是准确和完整的,因为后续的所有分析都建立在这个基础之上。
数据清洗
一旦收集了数据,下一步就是进行数据清洗,这个过程包括识别并删除错误的数据条目、处理缺失值、平滑噪声数据以及识别和删除异常值,数据清洗对于保证数据分析的准确性至关重要。
数据存储与管理
数据库选择
对于大数据量的存储,选择合适的数据库系统非常关键,传统的关系型数据库可能不适用于处理非结构化或半结构化的数据,许多组织转向NoSQL数据库,如MongoDB、Cassandra或HBase,这些数据库可以更好地处理大量的分布式数据。
数据索引和优化
为了提高查询效率,对数据进行适当的索引和优化是必不可少的,这包括使用合适的数据结构、优化查询语句以及实施高效的缓存策略。
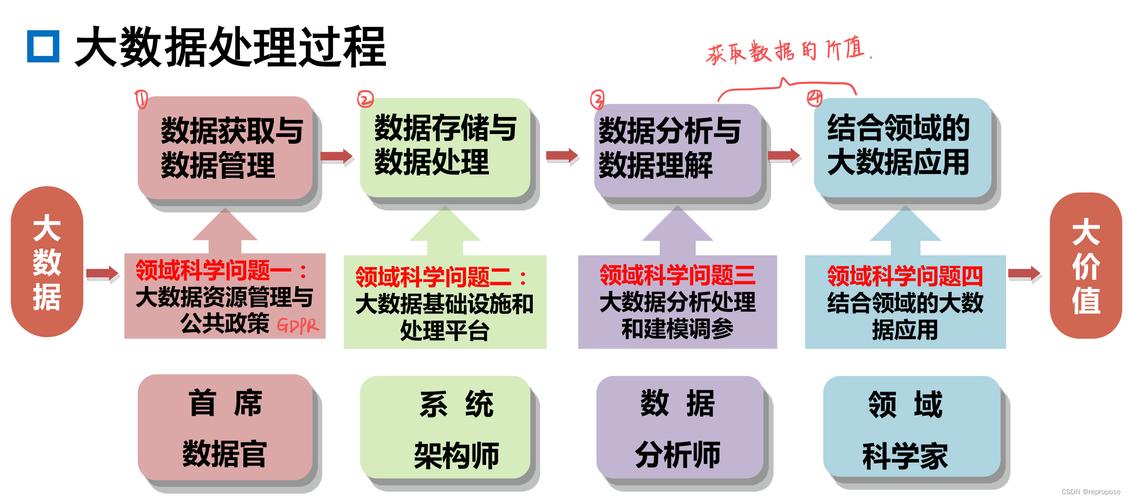
数据分析与量化
量化方法
数据量化是将数据转换为可度量的形式,以便进行分析,这可以通过多种方法实现,包括但不限于统计分析、机器学习算法和数据挖掘技术,可以使用回归分析来预测趋势,或者使用聚类算法来识别数据中的模式。
可视化工具
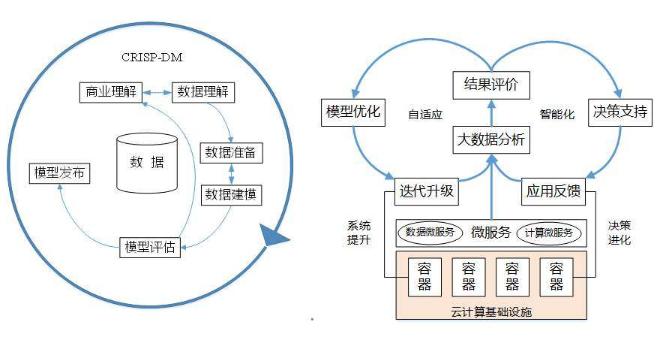
数据可视化是将量化结果呈现给最终用户的一种方式,有效的数据可视化可以帮助用户理解复杂的数据集,发现数据中的趋势和模式,常用的可视化工具包括Tableau、Power BI和D3.js等。
性能优化与扩展性
并行处理
处理大数据时,单线程处理往往不足以满足需求,采用并行处理技术,如Apache Spark或Hadoop MapReduce,可以显著提高数据处理的速度和效率。
云服务和扩展性
随着数据量的不断增长,本地解决方案可能变得不再适用,可以考虑使用云计算服务,如Amazon Web Services或Microsoft Azure,它们提供了可扩展的资源和强大的计算能力。
处理大数据量和内容数据量化是一个复杂但至关重要的过程,通过有效的数据收集、清洗、存储、分析和可视化,组织可以从大量数据中提取有价值的见解,以支持决策制定,采用先进的技术和工具,如并行处理和云计算服务,可以进一步提高处理效率和系统的扩展性。
相关问答FAQs
Q1: 如何处理缺失数据?
A1: 处理缺失数据的方法有多种,包括删除含有缺失值的记录、使用平均值或中位数填充缺失值、使用预测模型估计缺失值等,选择哪种方法取决于数据的性质和分析的需求。
Q2: 如何确保数据分析的准确性?
A2: 确保数据分析的准确性需要从多个方面入手,包括使用高质量的数据源、进行彻底的数据清洗、选择合适的分析方法和工具、以及进行结果的验证和测试,持续监控分析过程并对结果进行审查也是非常重要的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/743230.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复