


Redis共支持多种数据类型,包括基础和特殊类型,下面将对每种数据类型进行详细介绍:
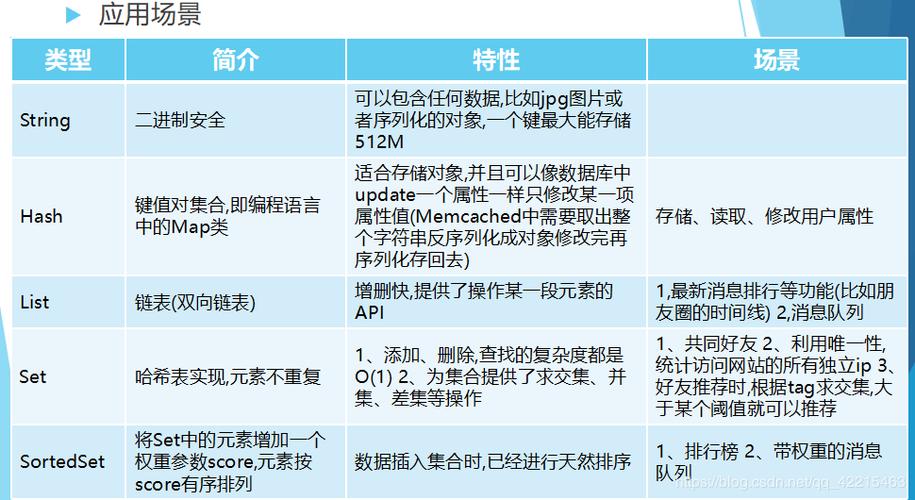

1、String(字符串)
基本概念:String是Redis中最基本的数据类型,可以存储字符串、整数或浮点数。
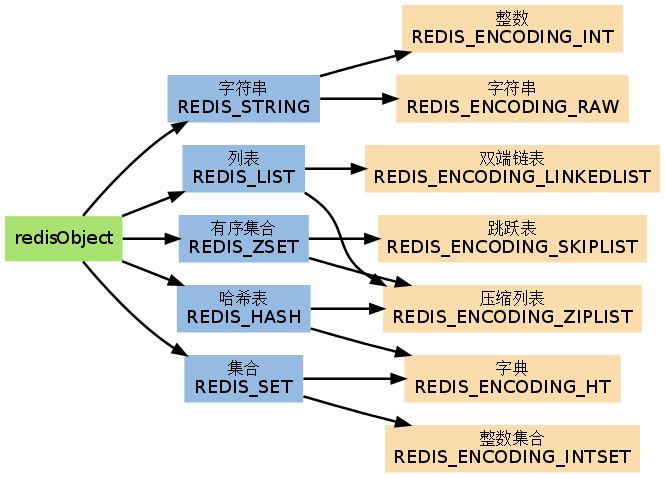
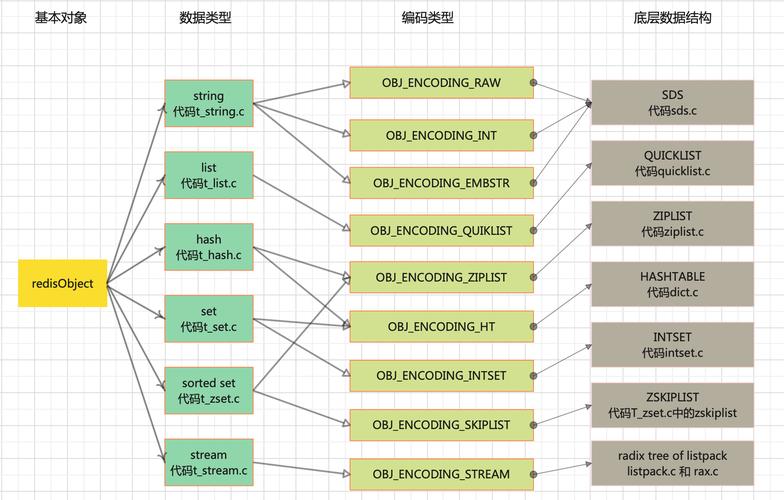
内部实现:底层的数据结构实现主要是int和SDS(简单动态字符串),SDS不仅可以保存文本数据还可以保存二进制数据,并且获取字符串长度的时间复杂度为O(1)。
常用命令:操作包括SET(设置键值对)、GET(获取键值)、INCR(自增键值)、DECR(自减键值)等。
应用场景:适用于缓存Session、Token、图片地址、序列化后的对象等。
2、Hash(哈希)
基本概念:Hash是一个键值对集合,适合存储对象。
内部实现:底层使用Dict(字典)和ZipList(压缩列表)实现。
常用命令:操作包括HSET(设置哈希表字段值)、HGET(获取哈希表字段值)、HGETALL(获取所有哈希表字段和值)等。
应用场景:常用于存储用户信息、配置信息等需要结构化的数据。
3、List(列表)
基本概念:List是简单的字符串列表,支持有序插入和删除操作。
内部实现:早期版本使用LinkedList或ZipList,新版本引入QuickList(快速列表),从Redis 7.0开始,QuickList被ListPack取代。
常用命令:操作包括LPUSH(在列表头部添加元素)、RPOP(移除并获取列表最后一个元素)等。
应用场景:适用于实现队列、栈等数据结构。
4、Set(集合)
基本概念:Set是无序且不重复的字符串集合。
内部实现:通过哈希表实现,添加、删除、查找的时间复杂度均为O(1) 。
常用命令:操作包括SADD(向集合添加一个或多个成员)、SREM(从集合中移除成员)等。
应用场景:常用于去重、好友关系记录等。
5、Zset(有序集合)
基本概念:与Set类似,但每个元素带有一个分数,用于排序。
内部实现:底层使用ZipList和SkipList(跳跃表)实现。
常用命令:操作包括ZADD(向有序集合添加成员)、ZREM(移除有序集合成员)等。
应用场景:常用于排行榜、时间线等需要排序的场景。
6、Bitmaps(位图)
基本概念:基于String类型,可以对每个位进行操作。
常用命令:操作包括SETBIT(设置指定位的值)、GETBIT(获取指定位的值)等。
应用场景:适合需要位操作的场景,如统计活跃用户。
7、HyperLogLogs(基数统计)
基本概念:用于基数统计,可以估算集合中的唯一元素数量。
常用命令:操作包括PFADD(添加元素到基数统计结构)、PFCOUNT(返回基数统计的近似值)等。
应用场景:常用于大数据去重统计。
8、Geospatial(地理空间)
基本概念:用于存储地理位置信息。
常用命令:操作包括GEOADD(添加地理位置)、GEODIST(计算地理位置间的距离)等。
应用场景:常用于物流跟踪、附近的人等功能。
9、Pub/Sub(发布订阅)
基本概念:一种消息通信模式,允许客户端订阅消息通道并接收发布的消息。
常用命令:操作包括SUBSCRIBE(订阅通道)、PUBLISH(发布消息至通道)等。
应用场景:常用于实现实时消息推送。
10、Streams(流)
基本概念:用于消息队列和日志存储,支持消息的持久化和时间排序。
常用命令:操作包括XADD(追加消息到流)、XREAD(从流中读取消息)等。
应用场景:适用于需要处理大量消息队列的场景。
11、Modules(模块)
基本概念:Redis支持动态加载模块以扩展其功能。
应用场景:通过开发自定义模块满足特定需求。
Redis提供了丰富而强大的数据类型,从基础的String、Hash、List、Set、Zset到特殊的Bitmaps、HyperLogLogs、Geospatial、Pub/Sub、Streams以及可扩展的Modules,每种数据类型都有其特定的应用场景和常用操作命令,合理选择和使用这些数据类型可以显著提升系统的效率和性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/742965.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复