


Apache Kafka是一个分布式流媒体平台,主要用于处理实时数据流。

Kafka最初由LinkedIn开发,使用Scala语言编写,并于2010年开源,之后迅速成为Apache的顶级项目之一,Kafka不仅用于消息传递,也是一个高性能的数据流处理平台,被广泛应用于构建实时数据管道和流式应用。
Kafka的主要特点包括高吞吐量、持久化存储、以及分布式操作,这些特性使得Kafka特别适合在大规模消息传递和实时数据处理的场景中使用,具体而言,Kafka的设计支持多分区和多副本的策略,这不仅提高了数据的可靠性,同时也为系统的水平扩展提供了便利。
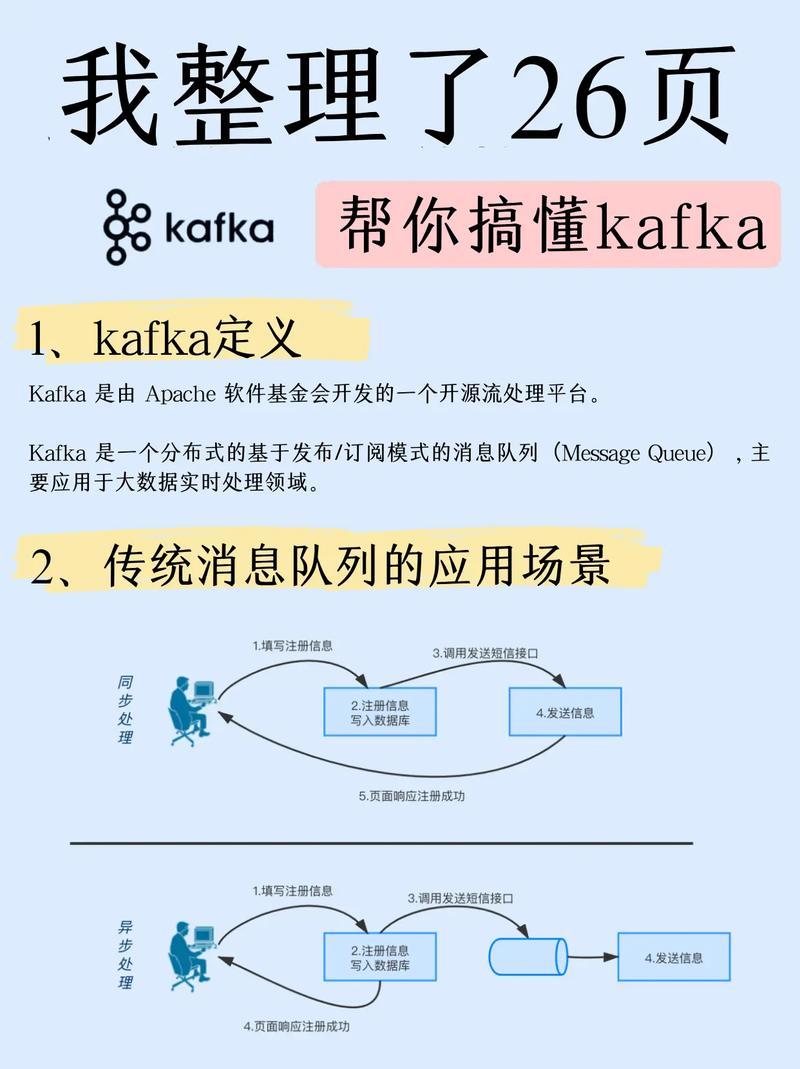
在Kafka的体系结构中,有几个关键的概念,包括生产者(Producer)、消费者(Consumer)、Broker和Topic,生产者负责将消息发送到特定的Topic,而消费者从这些Topic中读取消息进行处理,Broker是Kafka的服务节点,负责管理消息的存储和分发,每个Topic可以分为多个分区,这些分区可以分布在不同的Broker上,从而提高了系统的吞吐量和容错能力。
Kafka在数据处理方面的一个重要特性是支持消息的顺序性,在一个分区内,Kafka保证消息的发送和存储是有顺序的,这对于需要严格顺序处理的应用来说是非常重要的,Kafka还支持消息的回溯消费,这使得消费者可以重置到任意已知的偏移量(offset),重新消费过去的消息,对于系统调试和数据复审非常有用。
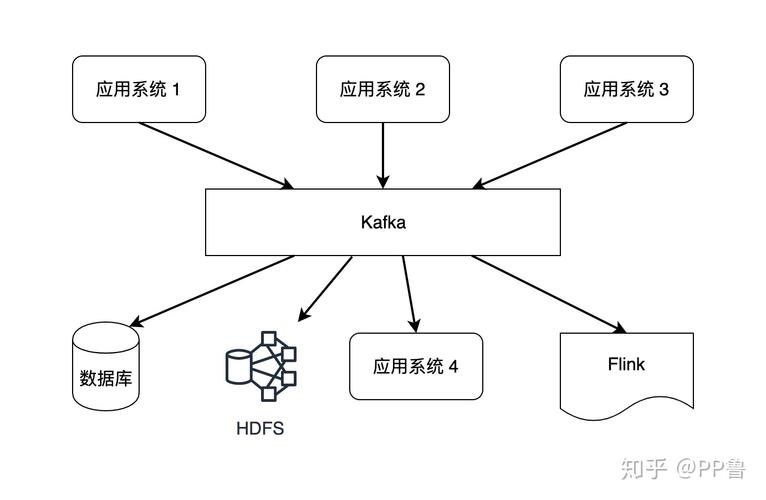
Kafka的用途非常广泛,从简单的消息队列到复杂的实时流处理,都可以看到它的身影,在日志聚合、实时分析、在线用户行为追踪等方面,Kafka都能提供有效的支持,由于其高吞吐量和低延迟的特性,Kafka也常被用于大数据场景中,作为数据流的收集和传输层。

Apache Kafka是一个功能强大的分布式消息系统和流处理平台,它以其独特的设计、高性能以及广泛的应用场景,成为了当今大数据和实时数据处理领域的一个重要工具。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/741637.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复