


在当今互联网时代,爬虫技术被广泛应用于数据采集与分析中,不法分子利用爬虫技术进行恶意攻击,如掠夺数据、侵犯版权等,给网站安全带来严重威胁,配置有效的反爬虫防护措施对于维护网站安全至关重要,本文将详细解析如何通过服务器配置实施反爬虫策略,以防御恶意爬虫攻击。
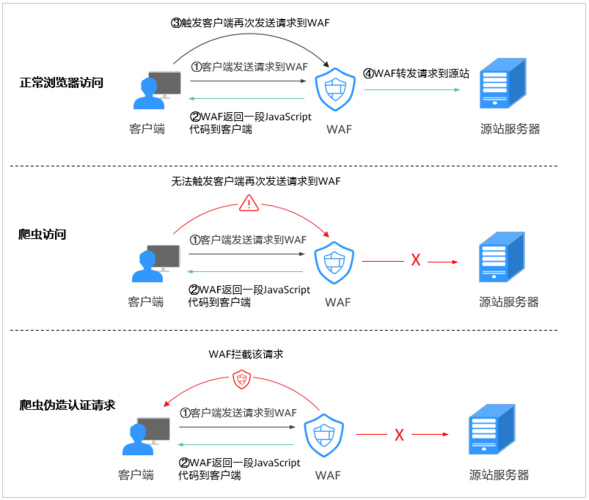

理解反爬虫的基本原理是制定防护规则的基础,反爬虫技术主要通过识别和区分正常用户行为与爬虫行为来实现防护,设置陷阱URL是一个常见且有效的方法,这些特殊设计的URL对普通用户是不可见的,但能被爬虫程序检测并访问,从而实现对爬虫的有效识别和屏蔽。
介绍几种具体的服务器配置反爬虫策略:
1、自定义JS脚本:通过实现复杂的JS脚本来检测用户行为,正常用户通过浏览器可以顺利执行JS脚本,而大多数爬虫无法正确处理或执行JS,从而暴露其身份。
2、WAF(Web Application Firewall):安装并配置WAF可以帮助网站拦截恶意爬虫,通过开启“网站反爬虫”功能,WAF能够检测并阻断各类爬虫程序,包括站点监控、访问代理、网页分析等。
3、特征反爬虫:在WAF中开启合适的防护功能,如针对特定HTTP请求特征、访问频率等进行限制,可以有效识别并阻止恶意爬虫的访问。
4、IP识别与封锁:分析日志中的访问模式,识别出爬虫使用的IP地址,随后在服务器上配置规则对这些IP进行封锁。
5、验证码和登陆验证:对频繁访问的用户提供验证码识别或者要求登录验证,以减少自动化爬虫的访问。
实施上述策略时需注意以下几点:
保持策略更新:随着爬虫技术的不断进化,需要定期更新防护策略,以应对新的爬虫手段。
平衡用户体验:在设置防护措施时,应避免对正常用户的访问造成干扰,确保良好的用户体验。
监控与响应:持续监控网站的访问模式,对异常行为及时做出响应,动态调整防护策略。
在配置反爬虫防护规则时,建议进行充分的测试,以确保防护措施既有效又不会对正常用户造成不便,了解最新的爬虫技术和防护方法也至关重要,因为这是一场不断发展的对抗。
FAQs
Q1: 反爬虫策略会影响搜索引擎优化(SEO)吗?
A1: 有可能,某些反爬虫措施,如JavaScript挑战或验证码,可能会影响到搜索引擎爬虫的正常抓取,进而影响页面的索引和排名,在实施反爬虫措施时,应确保不对搜索引擎爬虫产生负面影响,比如通过使用robots.txt文件指定搜索引擎爬虫可以访问的区域。
Q2: 如何避免误封正常用户?
A2: 在使用自动封锁IP等功能时,建议设置一定的阈值,如短时间内的访问次数,并在封锁前弹出验证码或进行人工确认的步骤,以避免误封正常用户,提供易于访问的申诉渠道,以便用户在被误封时能够快速恢复访问权限。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/740605.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复