

开启JS脚本反爬虫后,客户端请求获取页面失败的原因
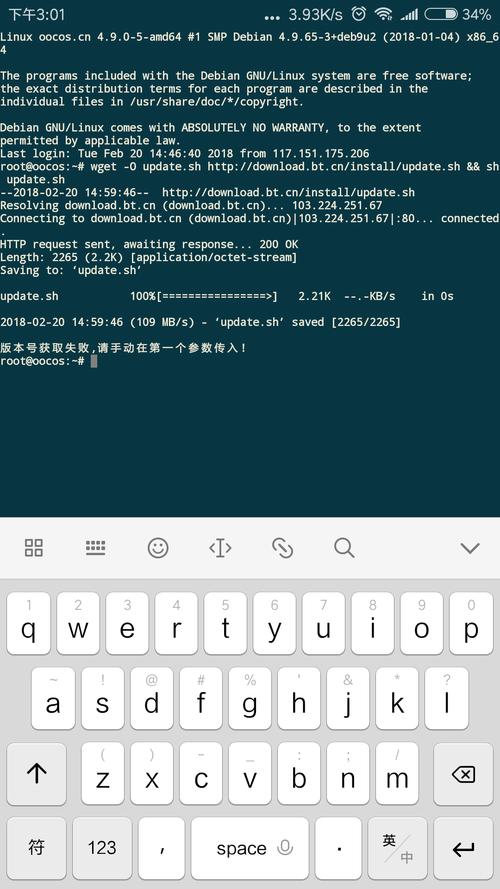
在互联网中,为了保护数据安全和防止恶意爬取,许多网站会采取各种反爬虫措施,通过JavaScript(JS)脚本来实现的反爬虫技术是一种常见的手段,当网站开启JS脚本反爬虫后,客户端请求获取页面可能会失败,主要原因包括以下几点:
1. 动态内容加载
问题描述:现代网站常使用AJAX(Asynchronous JavaScript and XML)技术动态加载内容,这意味着网页的主要内容并不是在初始HTML中直接提供的,而是在页面加载后,通过执行JS脚本从服务器端异步获取并渲染的。
影响分析:如果客户端请求时不执行JS脚本(例如使用传统的HTTP请求库如wget或curl),将无法获取到通过JS脚本动态加载的内容,导致页面显示不完整或为空。
2. 人机验证机制
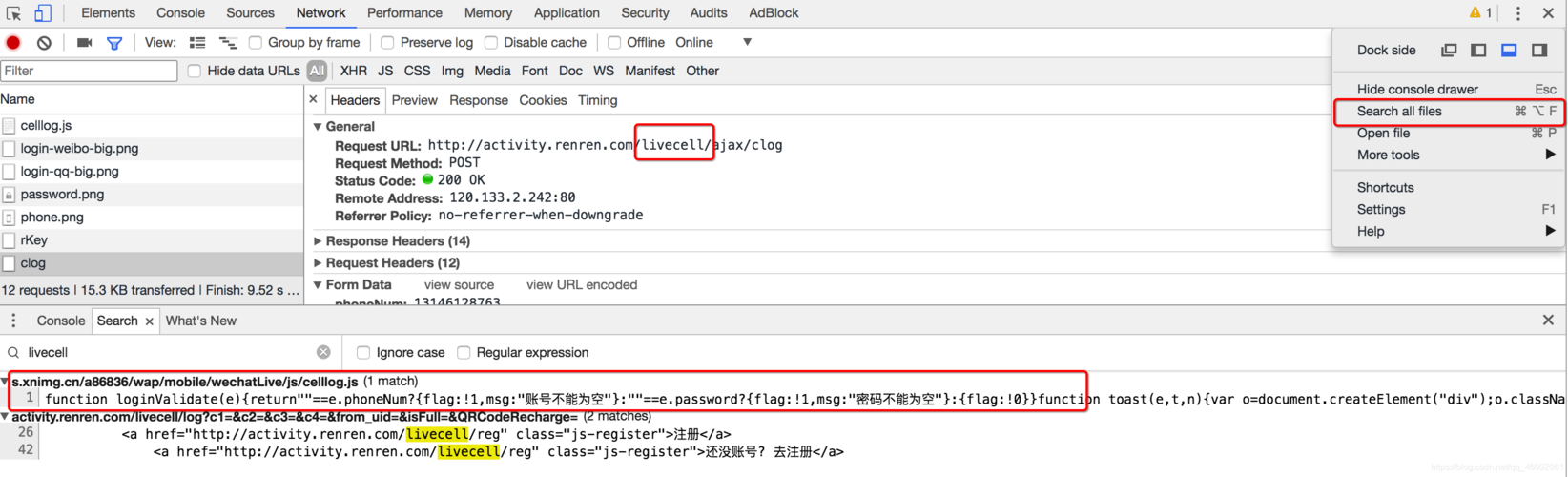
问题描述:为了防止自动化爬虫程序的访问,一些网站会在页面加载时通过JS脚本实现人机验证机制,如验证码、滑块验证等。
影响分析:这些验证通常要求用户进行特定的交互操作,如输入文本、滑动滑块等,普通的HTTP请求无法完成这些操作,因此无法通过验证,进而导致获取页面内容失败。
3. 浏览器特性检测
问题描述:部分网站会通过JS脚本检测访问者的浏览器特性,如浏览器类型、版本、支持的JS特性等。
影响分析:如果检测到访问者使用的不是常规的Web浏览器或者不支持某些JS特性,网站可能拒绝提供服务,返回错误信息或空白页面。
4. IP地址和访问频率限制
问题描述:通过JS脚本,网站可以设置对访问者IP地址和访问频率的限制。
影响分析:当来自同一IP地址的请求超过一定频率时,网站可能会暂时封锁该IP地址的访问,防止过度爬取数据。
5. 页面结构混淆
问题描述:一些网站通过复杂的JS脚本混淆页面结构,使得直接解析HTML内容变得困难。
影响分析:混淆技术包括但不限于使用不规范的HTML标签、动态生成DOM元素ID等,这些措施使得传统的爬虫难以定位和提取有效信息。
解决方案
面对上述问题,有几种常见的解决策略可以尝试:
1. 使用模拟浏览器行为的爬虫工具
方案描述:采用如Selenium、Puppeteer等能够模拟真实浏览器行为的爬虫工具,这些工具可以执行JS脚本,从而获取动态加载的内容。
优点:能够处理大部分基于JS的反爬措施。
缺点:运行速度较慢,资源消耗较大。
2. 使用代理IP和更换请求头
方案描述:通过使用代理IP和定期更换请求头信息,来绕过IP封锁和访问频率限制。
优点:简单易行,适用于小规模爬取。
缺点:对于严格的反爬机制效果有限,且可能需要支付额外费用购买代理服务。
3. 人工干预和机器学习
方案描述:对于复杂的人机验证机制,可以采用人工干预的方式解决,或者利用机器学习技术自动识别和解决验证码等问题。
优点:能够有效应对高难度的人机验证。
缺点:成本高,需要专业知识。
4. 合理遵守爬虫政策和法律法规
方案描述:在爬取数据前,应先检查网站的Robots.txt文件以及相关的爬虫政策,确保自己的行为符合规定,必要时,与网站管理员沟通获得允许。
优点:合法合规,避免法律风险。
缺点:可能无法获取到所有想要的数据。
开启JS脚本反爬虫后,客户端请求获取页面失败主要是由于现代网站大量采用动态内容加载、人机验证机制、浏览器特性检测等技术,面对这些挑战,爬虫开发者需要根据实际情况选择合适的策略和技术进行应对,合理遵守爬虫政策和法律法规,尊重网站的数据保护措施,也是每个爬虫开发者应当遵循的原则。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/739371.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复