


在现代数据分析和处理的领域中,Pandas库扮演着至关重要的角色,它提供了大量功能来操作和分析数据,特别是在处理结构化数据方面表现出色,本文将深入探讨如何利用Pandas对数据库进行分割和分区,旨在帮助读者更有效地处理大型数据集,避免潜在的内存问题,并提升数据处理任务的效率。
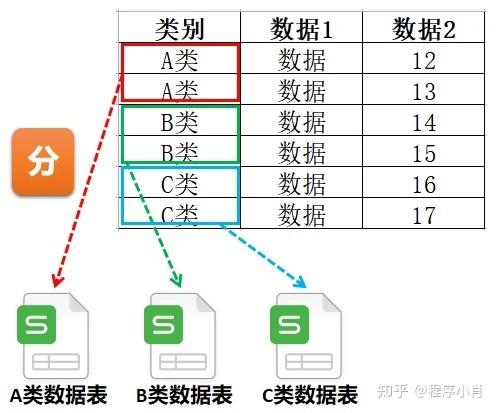

理解在何种情况下需要对数据库进行分割和分区至关重要,当处理的数据集规模巨大,无法一次性载入内存时,或者数据分析任务可以并行处理以提高效率时,数据库分割和分区变得非常必要,通过将大数据集拆分为较小的子集,我们可以更灵活地进行数据处理,同时减少单次操作所需的内存消耗。
按行索引分割Pandas数据框架
一种常见的数据库分割方法是按照行索引进行分割,这意味着根据数据的行号将其分成不同的区块,可以将一份有1万行的数据按照前5000行和后5000行分割成两个数据框,这种方法适用于数据集的顺序具有重要性的场景,比如时间序列数据,使用Pandas的iloc函数能够轻松实现这一点:
df_1 = df.iloc[:5000, :] df_2 = df.iloc[5000:, :]
这里,df_1包含了前5000行的数据,而df_2则包含了剩余的数据,通过调整索引值,可以灵活控制分割的界限。
按列值分割Pandas数据框架
另一种分割方法是根据列的值来进行分割,这对于需要根据数据的特性或类别进行分析的场景非常有用,比如在一个包含多种类型数据的数据集内,可能需要将特定类型的数据单独提取出来进行分析,Pandas提供了split函数来实现这一需求,假设有一个数据集,其中一列名为category,我们想根据这一列的不同值分割数据:
假设 df 是原始数据框,'category' 是列名
split_dfs = {k: v for k, v in df.groupby('category')} 上述代码会根据category列中的唯一值将数据框分割成多个小数据框,并将它们存储在一个字典中,其中键是列的值,值是对应的数据框。
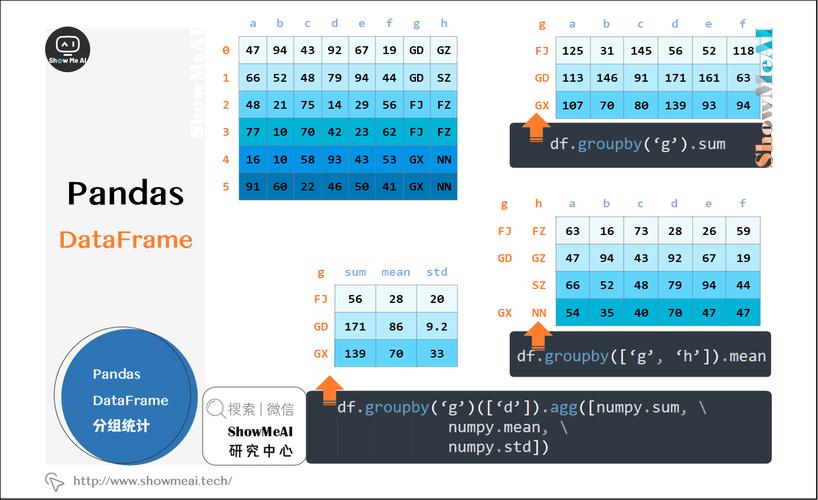
按列拆分
在某些情况下,可能只需要数据集中的某些特定列,而不是整个数据集,Pandas允许用户通过选择DataFrame中的所需列来拆分一个DataFrame,如果原始数据集非常宽,含有许多列,但分析任务只需涉及其中几列时,就可以采用这种方式:
假设我们只需要 'col1', 'col2'两列 df_new = df[['col1', 'col2']]
这样,新的数据框df_new就只包含了原来数据框中的col1和col2两列,大大减少了数据处理的范围和复杂性。
结合分割与实际应用
在实际的数据分析工作中,以上提到的分割方法往往不是孤立使用的,多数情况下,我们需要结合使用这些方法来满足复杂的数据处理需求,可以先根据行索引分割数据框,然后再根据列值进行进一步的细分,或者先筛选出需要的列,再根据行索引分割等,这种灵活的组合应用使得Pandas成为一个强大的数据分析工具。
效率考量与最佳实践
在进行数据分割时,还需要考虑分割的效率和最佳实践,避免创建过多小的数据框,因为这可能会导致程序运行效率降低,尤其是当涉及到大量的I/O操作时,适当选择分割的界限,确保每个分割后的数据子集都能够在可用内存中有效处理,合理利用Pandas提供的功能,如合理的索引使用、查询优化等,可以进一步提升数据处理的效率。
随着技术的进步,Pandas库也在不断更新和改进,为数据分析工作提供更多便利,掌握这些分割技巧,将有助于更好地利用Pandas处理和分析大规模数据集,从而在各种数据分析任务中发挥更大的作用。
相关问答FAQs
Pandas分割大数据时应注意什么?
在使用Pandas分割大数据时,需要注意以下几点:
1、内存管理:确保分割后的数据子集能够在可用内存中处理,过大的数据集可能导致内存溢出。
2、分割策略:根据数据处理的需求选择合适的分割策略,比如按行索引、按列值等。
3、效率考虑:避免不必要的数据处理步骤,尽量优化中间过程,比如通过合理的索引使用加速查询过程。
4、I/O操作:减少频繁的读写操作,尤其是在处理存储在磁盘上的大文件时,应尽量减少I/O次数。
5、数据一致性:保证分割过程中数据的一致性和完整性,避免数据丢失或错误。
Pandas中的分割和SQL中的分区有什么不同?
在Pandas中进行的“分割”主要是在数据处理层面,将数据集拆分成多个小数据集以便进行分析处理,通常是临时性的,主要用于数据处理和分析阶段,而SQL中的“分区”是一种数据库的设计技巧,用于永久性地将表的行分布到多个物理存储区域,旨在提高查询性能和管理效率,尽管两者都旨在处理大数据集,但应用场景和技术实现有所不同,Pandas的分割更多关注于内存管理和数据处理的便捷性,而SQL分区则是数据库层面的优化措施,关注的是查询性能和数据维护的便捷性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/735769.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复